
Adversarial training: a security workout for AI models
Adversarial training (AT) amends the training data of an AI model to make it more robust. How does AT fare against modern attacks? This post covers AT work presented at CVPR ’23.
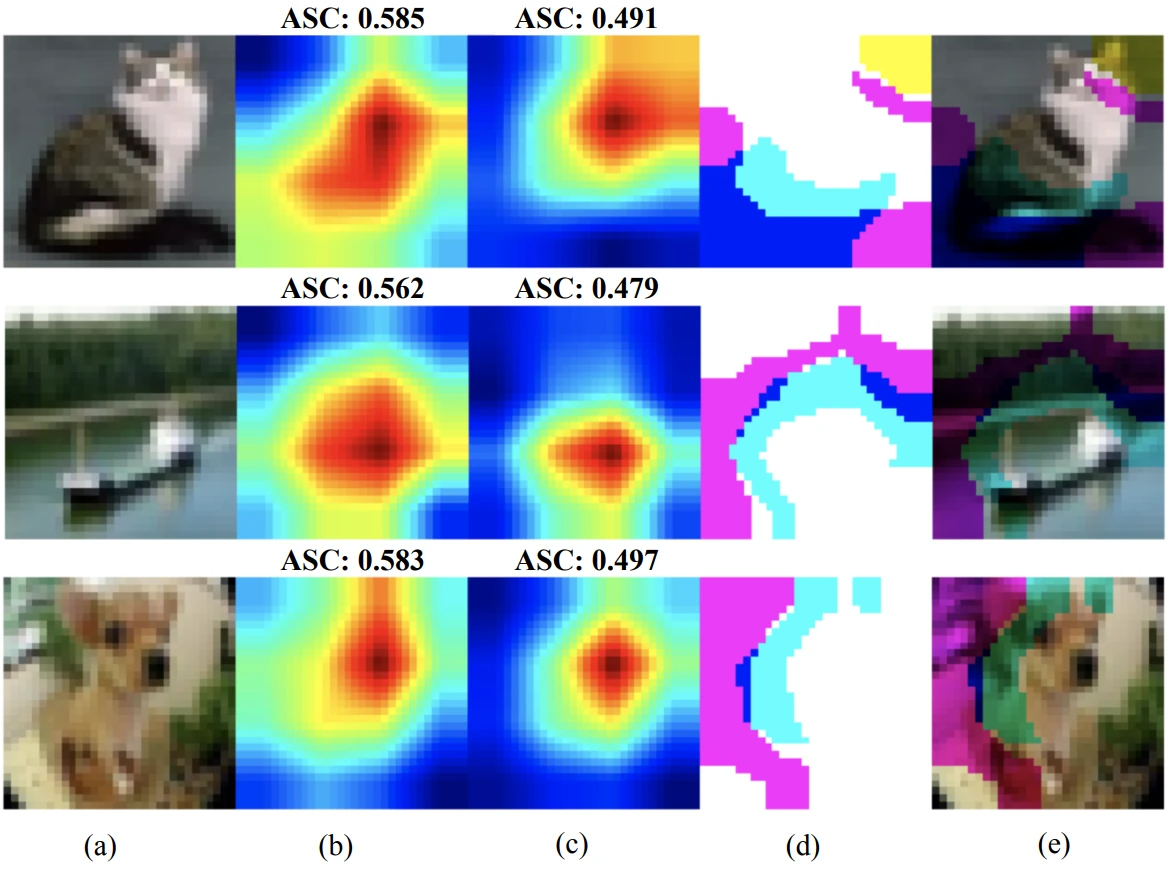
Adversarial training (AT) amends the training data of an AI model to make it more robust. How does AT fare against modern attacks? This post covers AT work presented at CVPR ’23.

Adversarial defense is a crucial topic: many attacks exist, and their numbers are surging. This post covers CVPR ’23 work on bolstering model architectures.
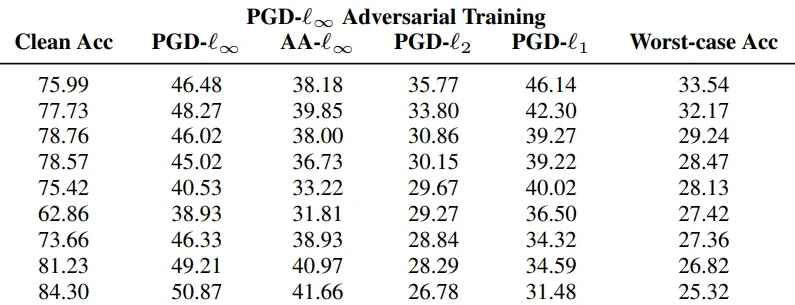
A mini-tool for comparison of adversarial defense of various computer vision model architectures, based on the CVPR ’23 work by A. Liu et al.

Physical adversarial attacks fool AI models with physical object modifications, harming real-world AI security. This post covers CVPR ’23 work on the topic.

This post summarizes the CVPR ’23 work on transferable attacks, optimized on a surrogate model controlled by the attacker to also work on black-box targets.

Adversarial attacks are a core discipline of AI security. This post summarizes pioneering adversarial attacks on computer vision models seen at CVPR ’23 that focus on underexplored tasks of computer vision or bring a new view on attack methodology.

The AI security papers from CVPR ’23 among the top-ranked papers by reviewer score.

CVPR ’23 has brought a large number of new, exciting AI security papers. This post kicks off a blog post series covering the work with an introduction, paper stats, and overall topical structure.

How is it possible that we can make anything look like something completely different in the eyes of an AI model? This post brings a real-world-inspired intuition of adversarial attacks on AI models.
All AI security papers from CVPR ’22 with paper link, categorized by attack type.