New adversarial attacks on computer vision from CVPR ’23
This post is a part of the AI security @ CVPR ’23 series. Adversarial attacks are a core discipline of AI security: attackers want to manipulate AI model input such that they get a response they want regardless of what the model was intended to output. The majority of AI security work at CVPR ’23, 47 out of 75 papers, deals with adversarial attacks: 24 present new adversarial attacks and 23 focus on defending them. This year, we have seen a lot of adversarial attacks that fall into either the “transferability” or “physical attacks” category. This blog post presents 6 new adversarial attacks on computer vision models that fall into neither category. The attacks described in this post focus on underexplored tasks of computer vision or bring a new view on attack methodology.
New frontiers for adversarial attacks
CVPR ’23 has seen two works that I consider pioneer attacks on their respective computer vision applications. Han Liu et al. (1) present RIATIG, an adversarial attack on text-to-image (T2I) models. One of the main security issues of T2I models is preventing harmful image outputs. With the right prompt, a T2I model can output explicit, offensive, hurtful, or privacy-breaching images. Proprietors of public T2I APIs such as DALL-E are aware of the issue, and one of the main countermeasures is scanning & filtering the prompts. An adversarial attack on a T2I model seeks to use an innocent-looking prompt to get a harmful image semantically similar to what would have been output if the model did not reject a harmful prompt. Fig. 1 illustrates this concept: assuming the top-row target images are harmful content, we can get very similar images using somewhat nonsensical, yet innocent-looking prompts. RIATIG optimizes the prompts using a genetic algorithm approach: a population of candidate prompts is refined through recombination and mutation. The winning prompt is then fine-tuned to further increase stealth.

Bu et al. present a pioneer attack on spiking neural networks (SNNs). SNNs are an emerging variant of neural networks that mimic the function of biological neurons more closely than classic perceptron-based neural networks (pNNs). Unlike pNN neurons that fire every time an input is presented, SNN neurons fire only when there is enough “pressure” on their membrane that accumulates over time. The output therefore depends on the neurons’ firing rate over time, which introduces the temporal aspect into SNNs. From the security point of view, SNNs have been considered somewhat more secure than pNNs due to the temporal aspect and the neuron spikes being discrete and therefore non-differentiable. However, Bu et al. show that this is not enough. Their rate gradient approximation attack (RGA), designed specifically for SNNs, performs differentiable attack optimization that approximates the neurons’ contributions to outputs by their average firing rate over a unit of time. SNNs are therefore not secure by design.
Exploring the underexplored
Two more works contribute new adversarial attacks in domains that I’d consider “underexplored”—there is an existing body of adversarial attack work, but the tasks still somewhat fly under the attackers’ radar despite their importance. Rony et al. present ALMA prox, an attack targeting semantic image segmentation. Segmentation assigns class labels on pixel level, splitting the scene into pixel regions with the same semantic meaning. Despite its position at the very core of computer vision, there are not that many existing segmentation attacks. Rony et al. argue that this is due to the nature of the optimization task with many constraints and the computational complexity. ALMA prox is based on proximal splitting, an optimization method that can split the cost function into a sum of terms that can be resolved by either gradients (if they’re smooth) or proximity operator (if they’re not). Furthermore, the authors present a novel segmentation attack evaluation metric. They argue that mean intersection over union is unsuitable to evaluate attacks on segmentation. They propose attack pixel success rate (APSR) that counts the ratio of wrongly classified (and therefore successfully attacked) pixels.

ALMA prox achieves very good results with >99% APSR, i.e., over 99% pixels are misclassified. Fig. 2 shows an example of a successfully attacked image from the CityScapes dataset. ALMA prox is also remarkably stealthy. Adversarial perturbations are commonly restricted to an \(l_{\infty}\) norm of \(\frac{8}{255}\). In other words, if you’d have an intensity slider with 255 steps for each pixel of the original image, 0 being black and 255 white, you can darken or brighten each pixel by up to 8 steps to construct the attack. ALMA prox on average achieves an \(l_{\infty}\) norm of less than \(\frac{1}{255}\). This means that on average, an ALMA prox adversarial attack brightens or darkens pixels by less than 1 intensity step. Fig. 3 illustrates the visual difference between a 1- and 8-step intensity difference. Overall, the ALMA prox paper ticks a lot of boxes for me. It opens up significant possibilities for a task that is certainly at the heart of computer vision, has good and stealthy results, and thinks about evaluation too. Certainly a strong paper!
Han Liu et al. (2) focus on attacking light detection and ranging (LiDAR) sensors. LiDARs are essential for correct operation of a number of technological applications. The most famous computer vision related application are autonomous vehicles. They need to be able to accurately measure distance to objects in their vicinity, and they need to do so in a timely manner. The SlowLiDAR attack targets the timeliness, increasing the LiDARs latency. The authors show their attack is stealthy and efficient against 6 most popular LiDAR-based detection pipelines, making it clear that this security problem needs serious attention.
Improving adversarial attacks methodology
The work of Williams & Li focuses on black-box sparse adversarial attacks. Mathematically speaking, sparse adversarial constrain their perturbation’s \(l_0\) norm, rather than the \(l_{\infty}\) norm. In other words, sparse attacks can change the intensity and color of individual pixels arbitrarily, but only up to a maximum number of pixels in the image. Williams & Li observe that if we minimize both norms jointly, we can achieve well-performing attacks that are far less conspicuous. They resolve the dual optimization objective problem by optimizing using an evolutionary algorithm, treating dominance of one objective over the other as a parameter. The proposed attack, SA-MOO, does outperform the state of the art whilst achieving higher semantic similarity to the original image than the competition. Fig. 4 illustrates that SA-MOO’s adversarial examples are indeed quite stealthy.

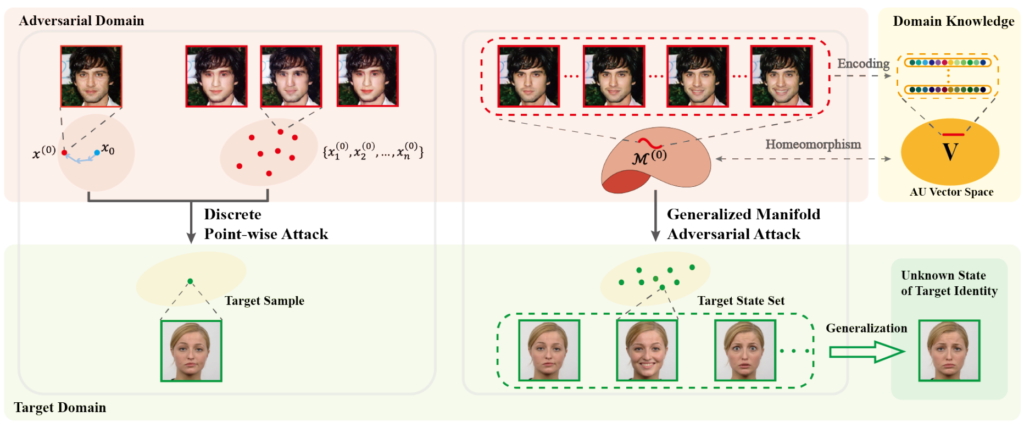
Q. Li et al. tackle face recognition. They argue that one of the main reasons for adversarial attacks’ poor generalization is overoptimizing to a single example. A single image results in a single adversarial example which may fail to fool the face recognition model if the model authenticates against a set of a person’s images. These images may be taken under slightly different conditions or display a different emotion. To bypass this, the authors propose a generalized manifold adversarial attack (GMAA) whose pipeline is depicted in Fig. 5. Instead of a single image, GMAA outputs an adversarial manifold that allows sampling of individual adversarial images. The authors use facial action coding system (FACS) as prior knowledge. FACS equips the manifold with the capability to semantically encode emotions in a vector space. The manifold therefore allows sampling adversarial images displaying different emotions. Interesting application, and it would be interesting to see if it generalizes to other tasks beyond facial recognition and thus enriches adversarial image diversity in the general case.
List of papers
- Bu et al.: Rate Gradient Approximation Attack Threats Deep Spiking Neural Networks
- Q. Li et al.: Discrete Point-Wise Attack Is Not Enough: Generalized Manifold Adversarial Attack for Face Recognition
- Han Liu et al. (1): RIATIG: Reliable and Imperceptible Adversarial Text-to-Image Generation With Natural Prompts
- Han Liu et al. (2): SlowLiDAR: Increasing the Latency of LiDAR-Based Detection Using Adversarial Examples
- Rony et al.: Proximal Splitting Adversarial Attack for Semantic Segmentation
- Williams & Li: Black-Box Sparse Adversarial Attack via Multi-Objective Optimisation
Subscribe
Enjoying the blog? Subscribe to receive blog updates, post notifications, and monthly post summaries by e-mail.