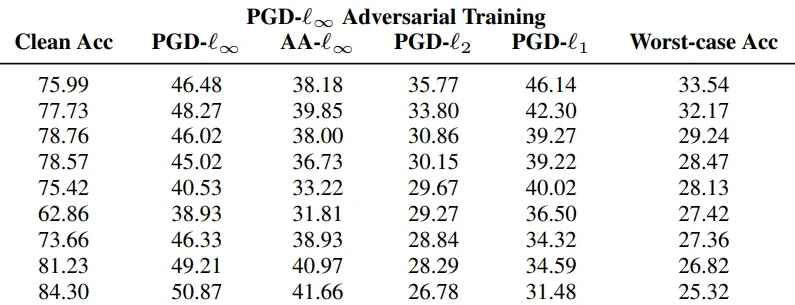
Judging LLM security: How to make sure large language models are helping us?
Introduction
Finally, I have some AI security work of my own to share, and the topic is LLM security. Without question, the year 2023 in AI has been the year of large language models (LLMs). Tools like ChatGPT, Bing Chat, or Google Bard are seeing adoption on an unprecedented scale, greatly speeding up text-related tasks such as writing or content summarization. Whether you’re an enthusiastic adopter of LLMs or a skeptic concerned about their impact, two things are certain. Firstly, LLMs are here to stay. Secondly, we need good LLM security: nobody legitimate benefits from unsafe, easy to manipulate AI, and LLMs are no exception.
With my colleagues Erik Derner, Kristina Batistič, and Robert Babuška, we’ve written a paper that introduces a comprehensive LLM security taxonomy:
Of course, I’d like to invite you to read the paper. I genuinely think it is one of the more accessible ones I have cowritten, it contains little heavily technical language and no math. To introduce the topic in a more informal manner, I will cover the paper in two blog posts. This one introduces the taxonomy proper and its key concepts. In the next post, we’ll look at some of the attacks that we conducted as a basis for it.
Motivation & contribution
LLMs are a godsend for attackers, for a number of reasons. Firstly, LLM security as a whole is still a new topic, so defense mechanisms are not mature yet. Secondly, LLMs introduce new attack surfaces: the attacker may target an LLM-powered business pipeline, or poison a general-purpose model. Finally, LLMs are versatile tools to craft attacks. There is virtually no topic where LLMs cannot produce relevant content. Yes, the content may only appear relevant to an expert, but that’s no problem for an attacker: they need to be good enough, not perfect. These reasons and more make it clear it’s high time we pay serious attention to LLM security.

Our taxonomy is intended to be practical contribution to LLM security. We provide a comprehensive, systematic way to look at LLM attacks, relevant to a broad audience of LLM stakeholders:
- LLM/app designers can use the taxonomy as a “security checklist” when designing the model or the app pipeline.
- The security team can use the taxonomy to build a proper security policy preventing LLM misuse. Our taxonomy is complementary to existing cybersecurity checklists for networks and general system access.
- General audience can use the taxonomy for quick verification of an LLM’s safety.
Before we dive into the specifics of the taxonomy, I’d be remiss not to mention the large survey effort that went into the paper. After filtering, the paper has 56 references. Rest assured our taxonomy is not something we dreamed up—rather, we take lessons from a large body of existing research and best practices.
The taxonomy
The taxonomy comprises two categorizations. The first splits the LLM attacks by the attacker’s goal, or what they seek to disrupt. We propose to simply use the old-and-gold CIA triad (Confidentiality-Integrity-Availability):
- Confidentiality — The attacker steals private information.
- Integrity — The attacker manipulates the target’s data.
- Availability — The attacker prevents the system from providing the intended service.
The CIA triad has been a cornerstone cybersecurity concept for many years now, and for a good reason: it works. Instead of reinventing the wheel, we simply highlight that it applies to LLM security as well.
The second categorization is new, and it categorizes LLM attacks by the attack target. Conceivable attacks include attacks users, the LLMs themselves, and third parties. Below, I break down these three categories. As a notation convention, bold red text indicates an attacker input, and strikethrough marks legitimate user input or LLM-generated text deleted by the attacker.
Attacks on users
The first target is a legitimate user that uses LLMs to boost their productivity. In this scenario, the attacker assumes the man-in-the-middle role, intercepting and manipulating the communication between the user and the LLM. Fig. 2 conceptualizes the attacks on users.

Eavesdropping on the prompts and/or responses compromises confidentiality, since the communication between a user and an LLM should be private by default. If the attacker can read the prompts, they can tamper with them to return false information: “write a false report about our Q3 financial results.” Alternatively, they can bloat the prompts such that the response is long-winded and unusable: “write a summary about Mozart’s work the work of all Classical era composers.” The attackers may also opt to tamper with the response: “Mozart, Beethoven, and Haydn Bartók, Debussy, and Mahler are famous Classical era composers”. These attacks can be defended by proper encryption and access policy on both the user and LLM sides.
If the attacker is able to capture the communication between the user and LLM, but cannot break the encryption, they can still cause damage by blocking the prompts or responses by dropping the corresponding network packets.
Attacks on LLMs
The LLMs themselves can be the target of an attack as well. In this scenario, an attacker is the user of the target LLM, and tries to manipulate the model into unintended outputs. Fig. 3 shows the types of attacks on LLMs.
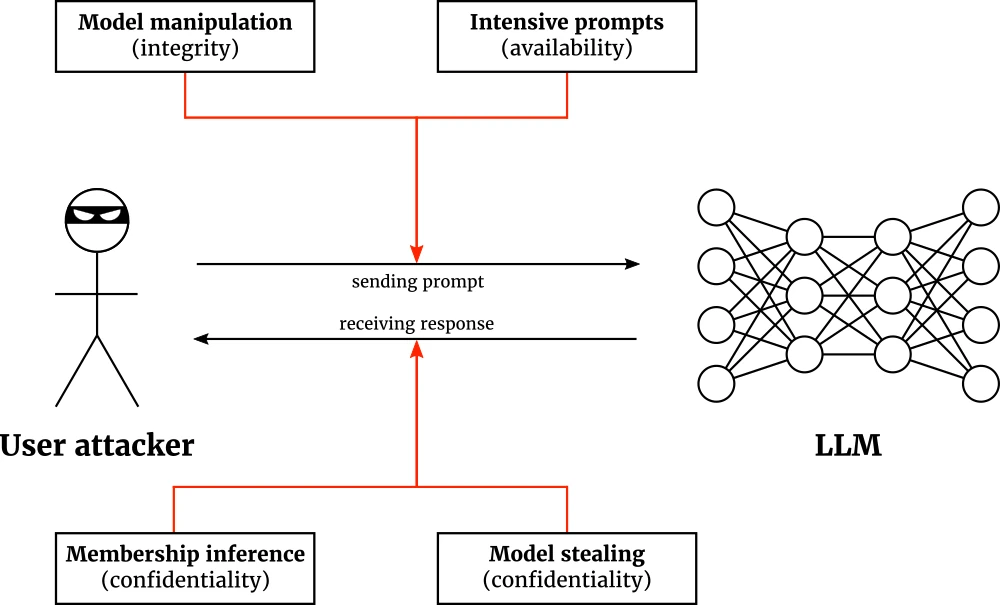
There are two conceivable attacks on confidentiality. Firstly, the attacker may be interested in stealing sensitive information present in the LLM’s training data through a membership inference attack. Secondly, the attacker may steal the model itself by a sequence of queries that provide the attacker with enough training data to train an LLM of their own. The success of both confidentiality attacks depend on the LLM response: a solid response crafting policy can therefore prevent leakage of unintended data.
Integrity can be compromised by a model manipulation attack that conditions the LLM to respond in a certain way, perhaps incrementally, over the course of a long session. As a defense technique, LLMs should be not so eager to listen to the user’s coercive instructions. Availability can be disrupted through intensive prompts: the attacker takes advantage of the fact that certain prompts take longer to process than others. Proper prompt frequency policies and computational quotas per user are key to prevent intensive prompt attacks.
Attacks on third parties
The final scenario are attacks on legitimate third parties: here, the malicious attacker uses an LLM to create or hone an attack on a third party. Then, the attacker deploy the attack later. The security of the user-LLM exchange itself therefore remains uncompromised. Rather, the LLM becomes the inadvertent attack tool. Fig. 4 provides an overview of attacks on third parties.
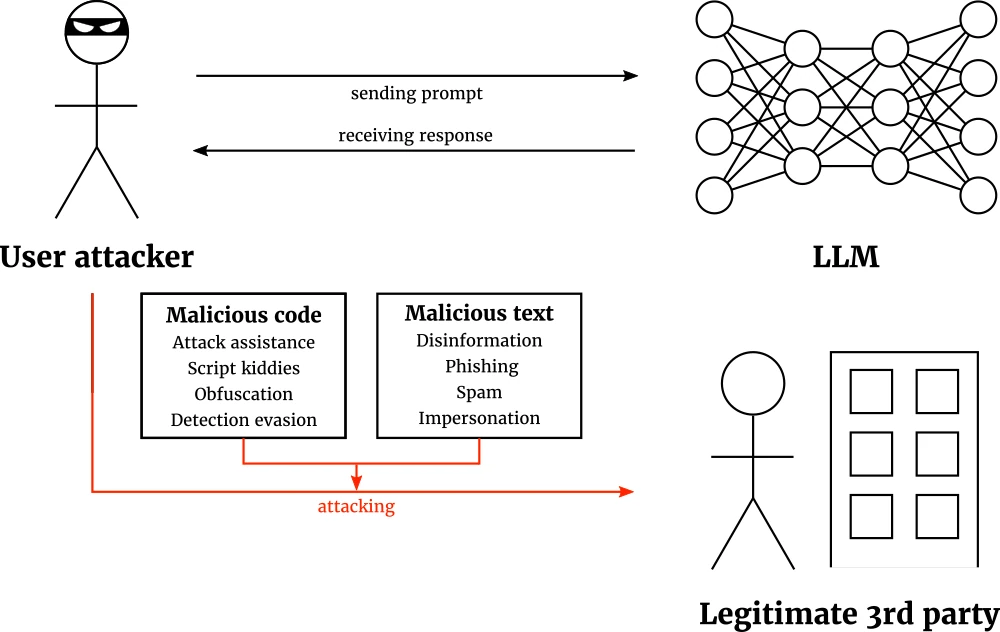
Third party attacks are a very broad category, since they can attack any conceivable third party. Roughly, these attacks break down into two subcategories. The first is malicious code: the LLM writes code that is then deployed for malicious purposes. The LLM can inadvertently provide attack assistance, enable script kiddies, or help conceal an attack by obfuscation and evading detection. The second is malicious text: LLMs can be used to spread disinformation more efficiently, write phishing or spam e-mails, or to impersonate someone. Due to the great variety of potential targets, there is no silver bullet defense solution. However, one important defense technique is common: raising LLM security awareness and alertness.
Conclusion
Beyond hoping you enjoyed this post, I hope you give the paper a read and more importantly, that you use our LLM security taxonomy. If you do and have any thoughts on it, don’t hesitate to reach out to me! At the very least, it gives a concise, yet poignant mental checklist that is useful to check whenever you encounter an LLM. Stay tuned for the next post which gives some insight into actual ChatGPT attacks that were conducted to provide a base for the taxonomy.
Subscribe
Enjoying the blog? Subscribe to receive blog updates, post notifications, and monthly post summaries by e-mail.