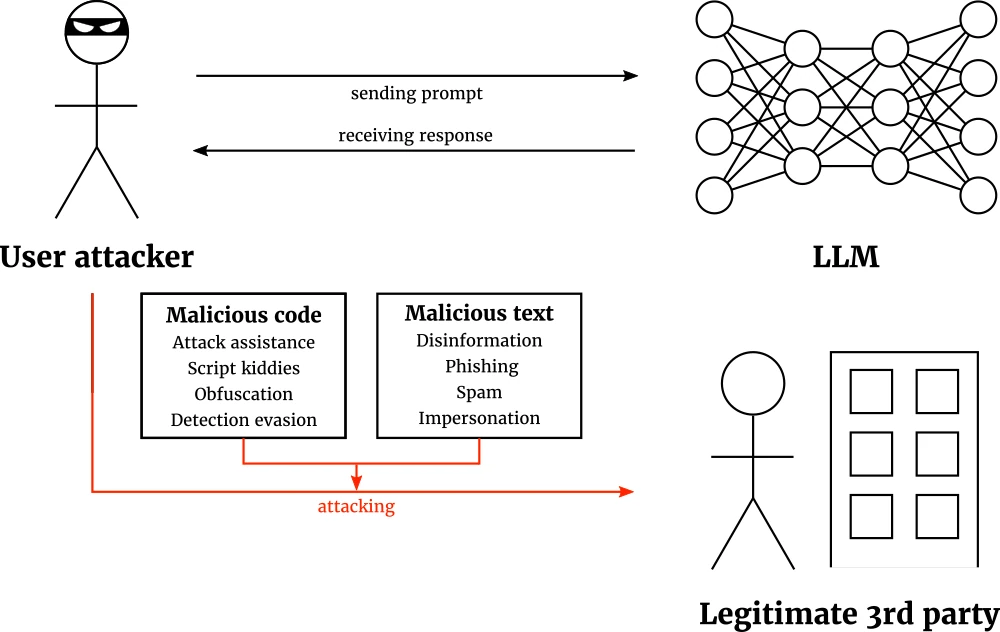
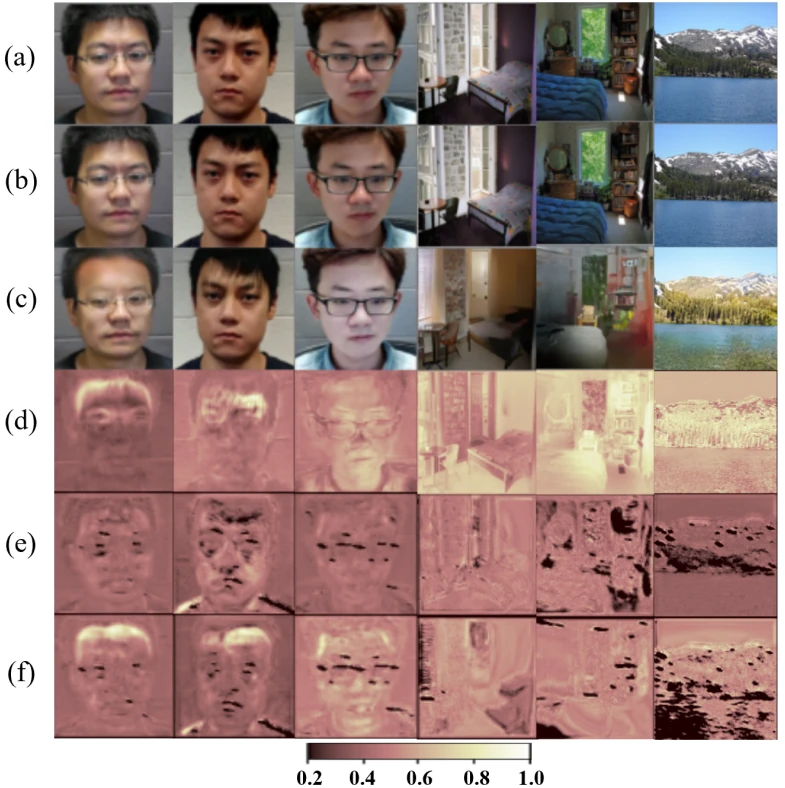
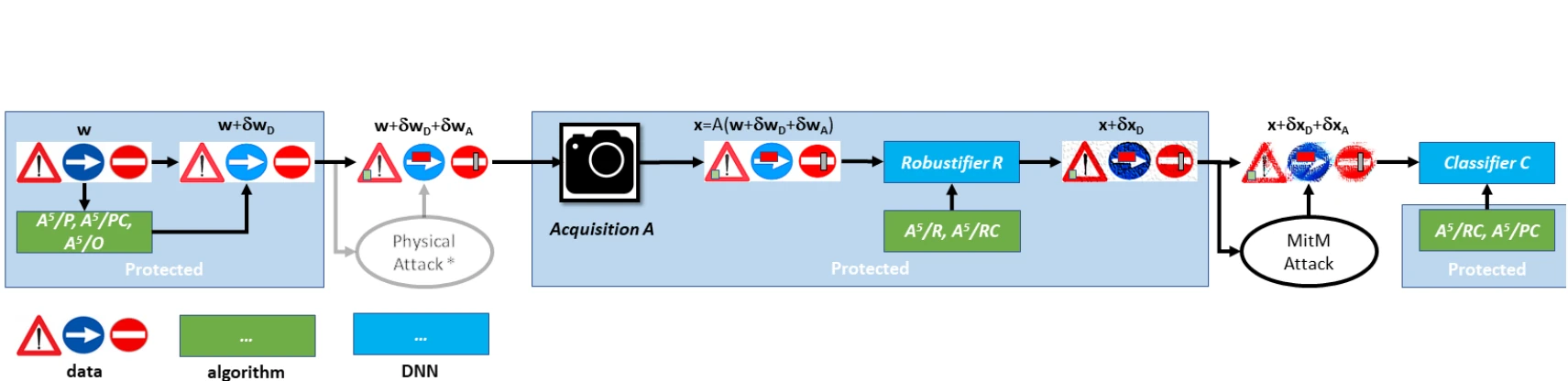
What’s more powerful than one adversarial attack?
Using a single attack won’t do, unless you are in a Hollywood film. This post covers AutoAttack, the pioneer ensemble adversarial attack, and shows how to test the adversarial robustness of AI models more rigorously.