The best AI security papers from CVPR ’23: Official highlights
This post is a part of the AI security @ CVPR ’23 series.
CVPR highlight papers & AI security
Every year, the best papers at CVPR according to the reviewers receive the highlight status. It is an important distinction. Essentially, a CVPR highlight paper has a “read this” stamp from the world’s best experts on computer vision. In this post, I happily follow their advice and summarize AI security papers that are also CVPR ’23 highlights.
There are 4 AI security highlight papers in total. Three out of the four are on adversarial defense, i.e., improving a model’s robustness to adversarial attacks. The fourth presents a very effective novel physical adversarial attack. Each of the four highlight papers is summarized in a separate subsection below, ordered by the first author’s last name.
If it’s broke, fix it
Highlight paper: W. Kim et al.: Feature Separation and Recalibration for Adversarial Robustness
Paper code: https://github.com/wkim97/FSR
One of the techniques to boost adversarial defense is to conduct an analysis of the model’s non-robust features and remove their influence. Adversarial attacks usually manipulate a small set of features, triggering an excessive response in the corresponding model units. This local excessive response blows up as the input propagates through the model and manipulates the model’s final output. If we can find the non-robust units—those that trigger the excessive response—then the established wisdom is to simply cut them out, removing their contribution to the output. W. Kim et al., however, propose to fix the non-robust units instead of discarding them. They argue that even non-robust units may capture valuable information that helps with an accurate output, and it is therefore wasteful to remove them outright.

The proposed feature separation & recalibration (FSR) method is conceptualized in Fig. 1. First, a separator net (\(S\)) learns to distinguish between robust (\(f^{+}\)) and non-robust (\(f^{-}\)) features. Features are robust if they contribute to the right decisions on clean images and non-robust if they contribute to the wrong decisions on adversarial images. Then, the recalibration net (\(R\)) fixes the non-robust features, resulting in a recalibrated feature vector \(\tilde{f}^{-}\) that correctly decides on adversarial examples. The final output of an FSR-equipped model layer aggregates the robust and recalibrated features. The main advantage of FSR is that it can be “clicked onto” any layer in a deep net model, making it highly modular and versatile. The experimental evaluation is convincing. The authors have evaluated FSR on a variety of models and datasets, showing robust accuracy improvements across the board.
Dividing & conquering adversarial robustness
Highlight paper: Wang & Wang: Generalist: Decoupling Natural and Robust Generalization
Paper code: https://github.com/PKU-ML/Generalist
This paper continues the theme of adversarial defense, this time focusing on adversarial training (AT). In AT, we add correctly labeled adversarial examples to the training dataset in hope that the model learns to classify them correctly despite the adversarial modifications. AT is a simple, powerful concept, but it comes with several issues. For one, AT introduces a second learning objective. In addition to increasing its natural accuracy (accuracy on clean images), we want the model to have a high robust accuracy (accuracy on adversarial images). However, natural and robust accuracy are at odds with each other—increasing one very often compromises the other. In this paper, Wang & Wang propose Generalist, a simple-yet-powerful idea: let’s optimize natural and robust accuracy separately.
Generalist trains three models with identical architecture: a global model that becomes the final model and two base learners, each optimizing one of the two accuracy metrics. The natural base learner accesses only the clean training images and optimizes natural accuracy, the robust base learner accesses only the adversarial training images and optimizes robust accuracy. All three models train separately, yet at the same time. The base learners communicate with the global model in cycles controlled by a communication frequency parameter (\(c\)). These cycles are essentially mini training epochs. The global model’s weights are an exponential moving average (EMA) of itself and a mixture of the base learner weights (the mixing ratio is another parameter, \(\gamma\)). At the beginning of each cycle, the timer for the EMA is reset. At the beginning of a cycle, the global model’s weights come mostly from its own learning. As time passes, the base learners perform better and therefore gain more influence on the global model’s weights.
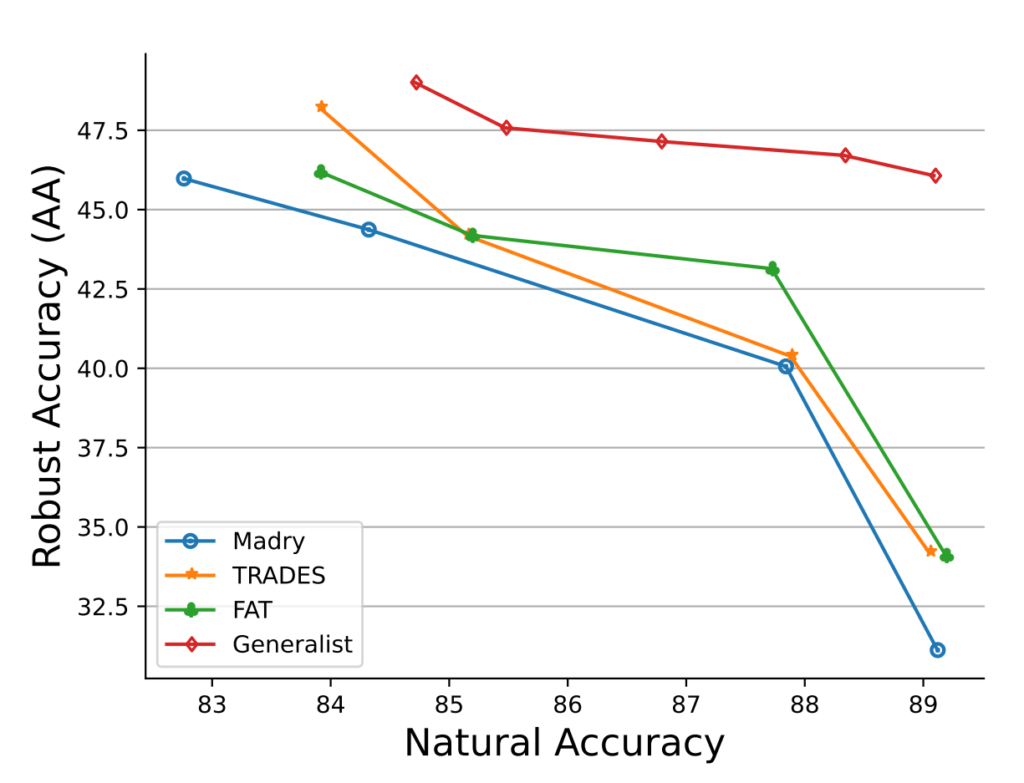
The experimental evaluation shows that Generalist is better than the competing strategies in the vast majority of scenarios. Its benefits are best illustrated by Fig. 2. It manages to reach top natural and robust accuracy whilst making the trade-off less severe than the competition. The authors also provide technical treatment of how to set the \(c\) and \(\gamma\) parameters. I personally view the parameters as the weakest point of the work as they are not very intuitive, but hey, that’s how it goes with parameters sometimes. Removing them/setting them dynamically might be an idea for future work. That said, this is overall quite an exciting work well deserving of its highlight status.
Bounding robustness, probably approximately correctly
Highlight paper: Zifan Wang et al.: Improving Robust Generalization by Direct PAC-Bayesian Bound Minimization
This is the third highlight paper on adversarial robustness, this time focusing on the problem of robust overfitting: high robust training accuracy, atrocious robust generalization accuracy. In other words, an adversarially-trained model does not get fooled by training adversarial examples, but fails on adversarial examples not seen during training. The authors propose the TrH method reducing robust generalization error by regularizing the trace of Hessian in the top layer of the trained model. Whoa, how did we get from the problem to the solution? Well, this is quite a technical paper with a lot of preliminaries. Whilst I usually consider highly technical papers a slog, this one was genuinely enjoyable to read for me. I think it ties nicely to machine learning fundamentals I hold so dear. So here’s my attempt at breaking it down.
This paper joins the family of PAC-Bayesian bound methods to reduce robust generalization error. PAC-learning is an old, but gold machine learning concept introduced by L. Valiant in the 1980s. It stands for “probably approximately correct”: PAC-learnable problems are those where you can mathematically guarantee that the generalization error is below the given threshold (“approximately correct”) with a given probability (“probably”). Inspired by this concept, a PAC-Bayesian upper bound on robust generalization error means guaranteeing that the robust generalization error is bounded within a certain distance from the robust training error. In other words, given a model with a certain robust training error, we can be pretty sure that its robust generalization error is not much worse. The authors of this paper note that the PAC-Bayesian bounds presented in previous works are intractable to compute. They therefore develop a tractable linear-form PAC-Bayesian bound. This bound hinges on the robust training error and, indeed, the trace of the Hessian (TrH) of the robust loss. Regularizing TrH therefore improves the robust generalization of the adversarially-trained model.
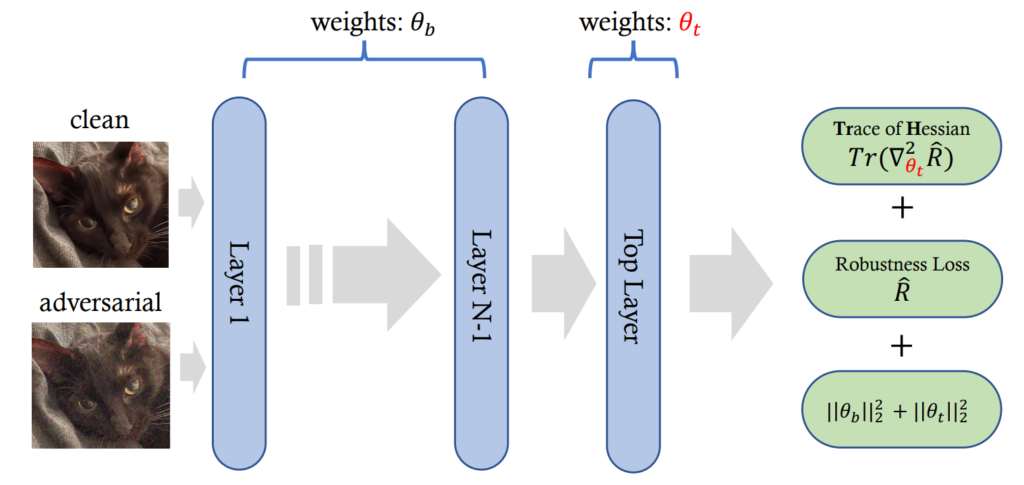
There are two issues here. Firstly, this conclusion assumes that the prior distribution of the model’s weights is a Gaussian and the posterior is a product of univariate Gaussians. The paper does not elaborate on this at all, which is a pity. Secondly, computing TrHs for a large model may be feasible, but computationally very expensive. Fortunately, the authors address this important issue: turns out it is enough to just regularize TrH for the output layer of the model. The paper convincingly shows that not much performance is lost this way, and the computational discount is considerable. With all key ingredients in place, finally the high-level conceptualization in Fig. 3 (hopefully) makes sense. TrH is shown to never degrade and mostly improve adversarial robustness. The authors observe a stronger positive effect on ImageNet, which is closer to a real-world dataset than CIFAR. I think this is overall an exciting work that leverages the fundamentals of machine learning quite well.
Shattering face recognition
Highlight paper: Yang et al.: Towards Effective Adversarial Textured 3D Meshes on Physical Face Recognition
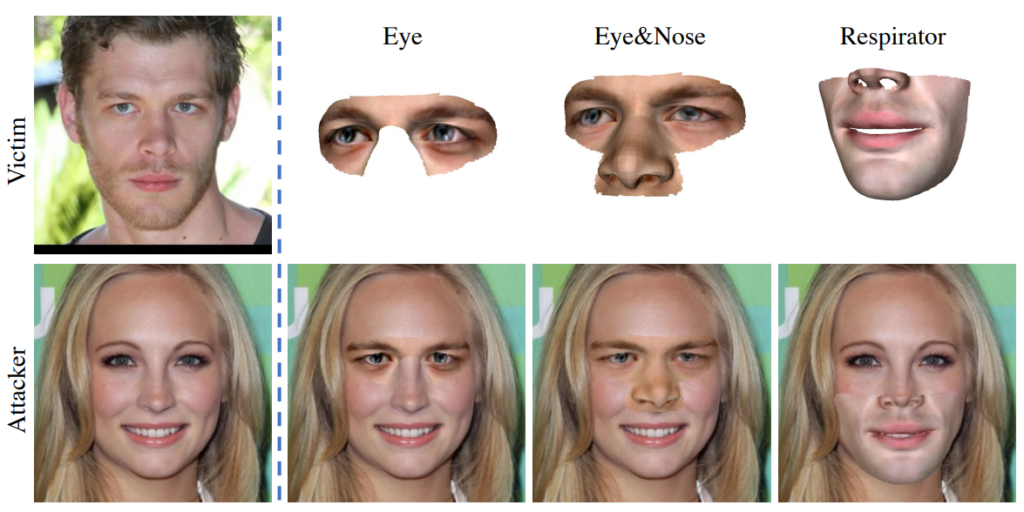
After three papers leaning towards the more technical, theoretical topic of adversarial defense, let’s have some fun with smashing things up! The highlight paper by Yang et al. is on physical adversarial attacks against face recognition models. One would be hard pressed to find a more iconic example of a security-sensitive computer vision application than face recognition. Face recognition models protect our mobile phones, grant passage to restricted areas, or can be used to track people and spy on them—both attacks and defense therefore have legitimate use cases. In this paper, Yang et al. propose AT3D, or adversarial texture 3D meshes worn on one’s face to fool a face recognition model.
The method involves creating a 3D mesh using identity, expression and texture coefficients from a trained convolutional neural network. The resulting AT3D mesh contains elements of the target’s identity, blended with the attacker’s own features to create a mask worn over the attacker’s face. The mask comes in three variants: an eye mask, an eyes+nose mask, and respirator-style mask covering the lower half of the face. The masks are showcased in in Figs. 4 and 5: while they may struggle to fool anyone in a face-to-face encounter, that is not the point. The point is to fool face recognition models and anti-spoofing methods featured in them and there, they do succeed. I’d argue that it is the experimental evaluation section where the true strength of the paper lies: AT3D shows a devastating success against face recognition state of the art.

In the experimental evaluation, the authors pit AT3D against widely-used state-of-the-art face recognition APIs (Amazon, Face++, Tencent), anti-spoofing mechanisms (FaceID, SenseID, Tencent, Aliyun), two leading mobile phones, and two surveillance systems (the latter two categories kept anonymous not to compromise user privacy & security). The attacks (example in Fig. 5) boast a high attack success rate, especially those using an eyes+nose mask. The authors have conducted a rather large physical-world experiment with 50 attacker-target pairs that confirms the success of the method. Overall, the AT3D paper is certainly an impressive piece of work with immediate practical consequences.
Subscribe
Enjoying the blog? Subscribe to receive blog updates, post notifications, and monthly post summaries by e-mail.