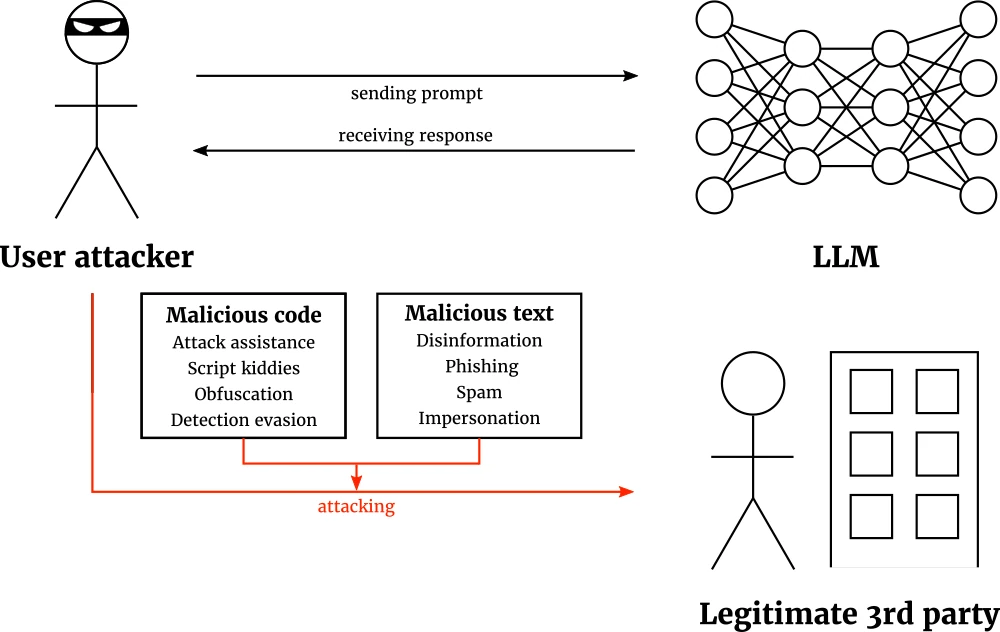
From one model to another: Transferable attacks research @ CVPR ’23
This post is a part of the AI security @ CVPR ’23 series. One of the most important attributes of an adversarial attack is whether it is white-box or black-box. In the baby years of AI security, the community was still learning the ropes, so virtually all research was on white-box attacks. Recently, the interest has shifted to black-box attacks. That is the realistic scenario attackers face in practice, because their targets of course keep their models private. In the black-box setting, the attacker optimizes their attack on a surrogate model that emulates the target. There are two main strategies. The first is query-based, trying to elicit enough labels from the model such that the surrogate can be trained to be similar enough to the target model. However, this requires a lot of labels, and query-based attackers often hit the request limit in modern AI APIs. The second approach is to construct transferable attacks, that is, to employ strategies that make the attacks optimized on the surrogate model general enough to work 1:1 on the target.
This post focuses on transferable attacks. CVPR ’23 has seen 11 papers on the topic. The connecting thread between almost all of them is that they focus on targeted attacks. Targeted attacks attempt to change the true class of the input into a particular class of the attacker’s choice. Targeted attacks are much more challenging than untargeted attacks that succeed if the true class is changed into any other class. This strong research direction is new. CVPR ’22 has brought fewer papers on transferable attacks in total, and fewer still on targeted transferable attacks. Another interesting aspect of most of the CVPR ’23 work is that the transferable attacks are highly modular: they can be “clicked onto” existing adversarial attack methods. In most cases, I’d say they’d supplement each other. It could be fun to see a “super-transferable CVPR ’23 attack” that combines as many of the proposed methods as possible…
The transferable attacks mostly fall into two categories. Firstly, 5 papers on attacks seek to improve transferability by strategies related to properly leveraging class concepts. Secondly, 3 papers on attacks mitigating model differences. Finally, 3 papers present transferable attacks that do not strongly fall into any of the two categories. The papers are summarized per category below.
Heart of the classes
If we’d assign human characteristics to adversarial attacks, one of the reasons they fail to transfer properly is their laziness. Adversarial attacks don’t really learn the underlying concepts of the classes they want to subvert. On the contrary, by design they go for the lowest-hanging fruit, the model’s blind spot closest to the original image. However, these blind spots tend to be specific to the one model the attack optimization is running against. Perhaps a misfiring feature, perhaps the training data has not been general enough for a certain class… This of course prevents transferability: the target model’s fruit may not be hanging so low, or it may be hanging low from a different branch. Transferable attacks, especially targeted transferable attacks, need to be based on the underlying concepts of the true and target classes, rather than specific model glitches.
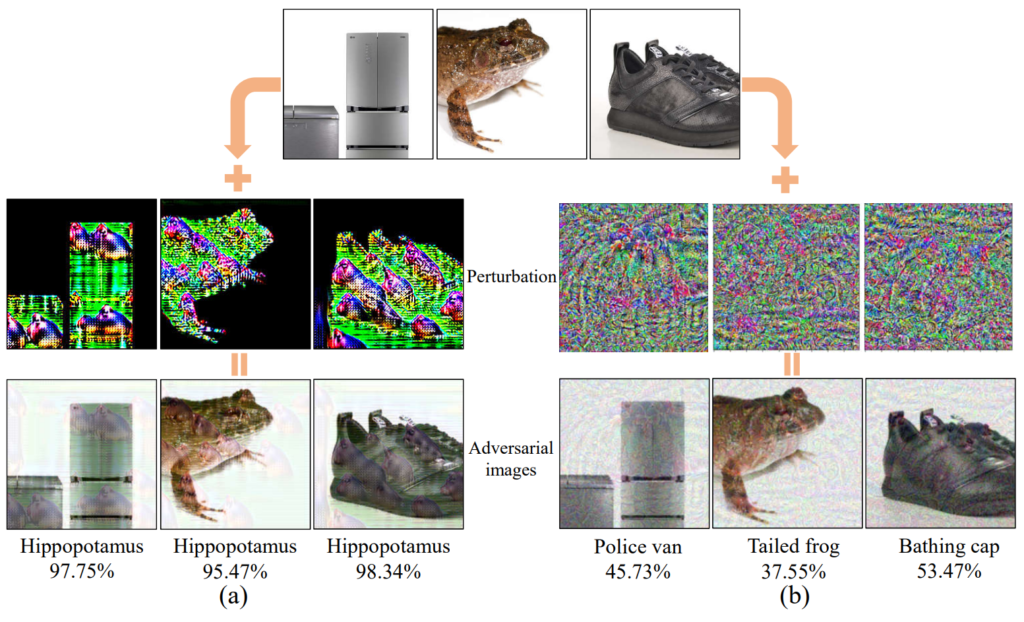
The work of W. Feng et al. is a prime example of an attack that doesn’t want to be instance-specific, but rather leverage the information at the heart of the true and target classes (instance-agnostic). They propose to use adversarial patterns: think subtle camouflage that changes e.g., a fridge, frog, or a pair of shoes into a hippopotamus (see Fig. 1). This paper is a standout for me for two reasons that are both visible in Fig. 1. Firstly, we can see that the “hippo pattern” shares some commonalities between the various objects—personally, I think I see the patterns featuring the distinct shape of a hippo’s eyes. Classic perturbations act more like random noise, which prevents a similar analysis. Secondly, I feel the pattern attack is visually subtler than the classic perturbation. This is certainly a stand-out paper for me.
Two papers aim at avoiding overusing local information in the images. Byun et al. propose to shuffle image features during attack optimization in a probabilistic manner. This means that with a certain probability, the given feature’s activation on a given adversarially modified image is replaced either by the same feature’s response on the same clean image or the same feature’s response on a different clean image. The first case prevents overoptimizing to a small feature set, the second may introduce features from a different class (it’s a different image), increasing pressure on capturing the inherent class information in the attack. Zhipeng Wei et al. propose focusing on self-universality: instead of optimizing each adversarial perturbation for just one particular image, the same perturbation is optimized for a set of images featuring the image and random patches cut out from the image and resized to the same size as the image. This makes the attack locality-invariant.
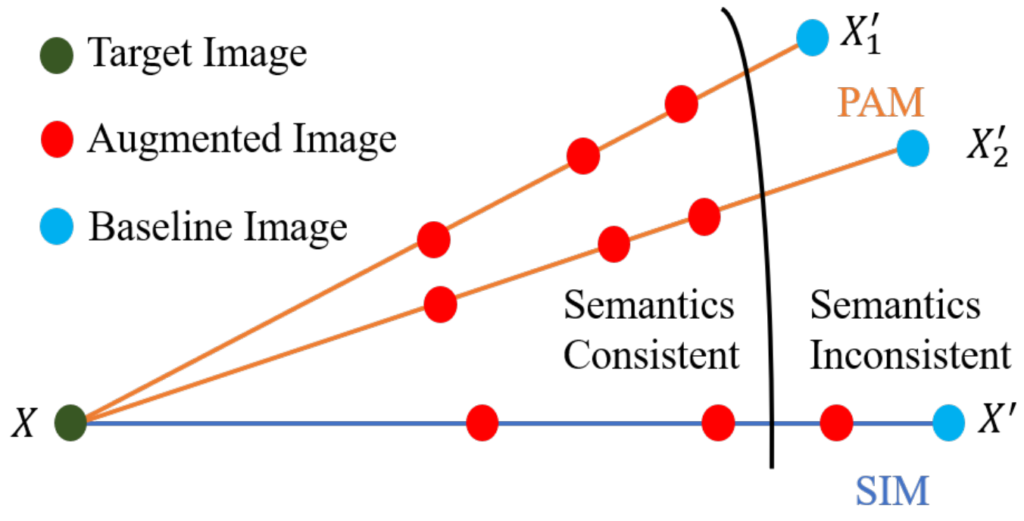
“Drop your style” might sound like a weird advice in general, but it seems like a good one for transferable adversarial attacks. Liang and Xiao observe that deep nets are naturally more robust to attacks w.r.t. the actual content of the class, and not robust against the style of the image. That makes sense: training sets are specifically crafted to consistently capture what actually represents the class in various settings, but image style is usually not a primary concern. This is a problem for attack transferability: image style becomes the aforementioned low-hanging fruit that attack optimization goes for. The StyLess attack proposed in this work forces the optimization to focus on the content by injecting the images with various styles. Speaking of “injecting the images” more broadly, Jianping Zhang et al. (1) propose to improve the augmentation-based path towards attack transferability. Augmenting images can make the dataset more robust to random variance, but must be done properly. The concept is illustrated in Fig. 2: the proposed method augments along multiple paths, ensuring only semantically consistent images make the cut. To decide semantic consistency, a lightweight model is used.
Model differences
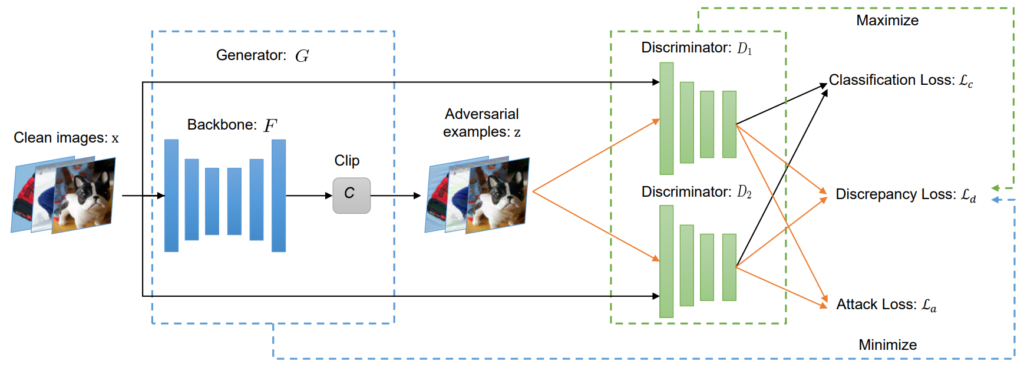
Another key issue for transferability is the difference between the surrogate and target models. In the black-box setting, perhaps we can make reasonable assumptions about the target which helps us with our choice of a surrogate model, but we do not know for sure. Therefore, the models will be different, and that is a challenge. A. Zhao et al. set and prove an upper bound on generalization error of a transferred attack. Indeed, this upper bound hinges on the empirical error on the surrogate model and the discrepancy between surrogate and target model architectures. Their proposed M3D attack realizes the discrepancy term by engaging two discriminator models enabling the inclusion of an explicit model discrepancy loss. The pipeline is illustrated in Fig. 3.
Model ensembling can alleviate the difference between surrogate and target models too. Instead of a single surrogate model, we employ an ensemble of various surrogate models. Attacks aggregated across an ensemble tend to be more general, and therefore transferable. Interestingly enough, the two papers centered around ensembling take somewhat opposing stances to the topic. Cai et al. fully lean towards the idea of ensembling, proposing an ensemble attack on dense prediction tasks (object detection and segmentation) that allows customizable weight balancing and weight optimization. H. Huang et al. also consider ensembling a worthy idea in general, but they highlight its specific problems. Namely, if it is difficult to find one good surrogate model, finding multiple less-than-optimal surrogates may compound the errors. Also, optimizing on multiple models is computationally costly. To reconcile this, they propose self-ensembling: finding a reasonable surrogate model and then ensembling it with variants of itself that drop out certain layers using ShakeDrop from Yamada et al.: ShakeDrop Regularization for Deep Residual Learning (IEEE Access 2019). To further increase generality, H. Huang et al. randomly cut out patches from the optimized images.
Uncategorized transferable attacks
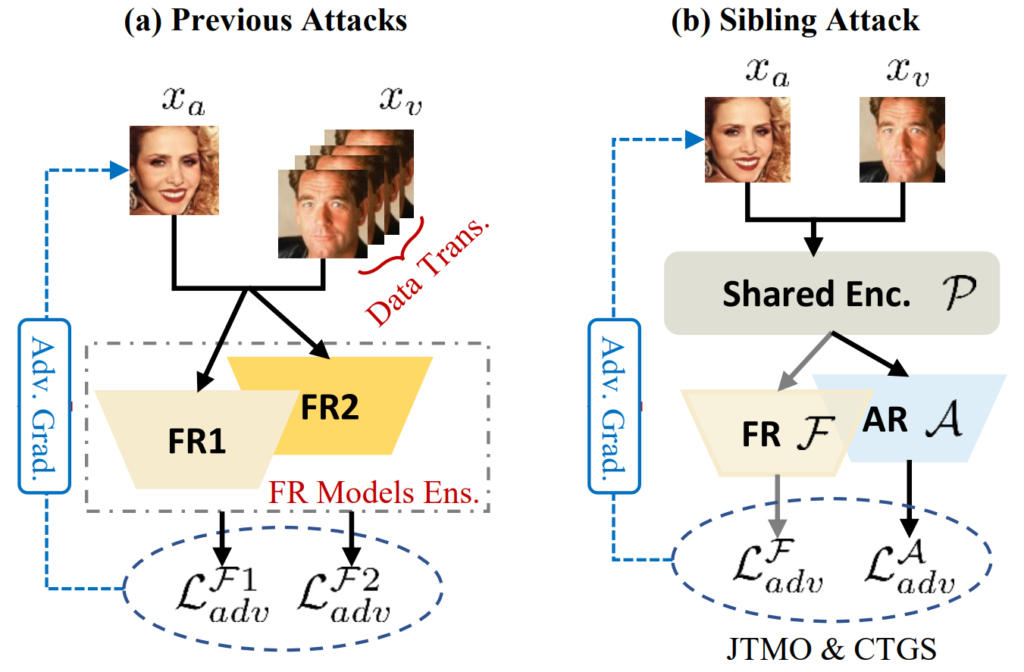
Last, but not least, this section introduces the three papers falling outside of the two categories. Z. Li et al. propose the sibling attack on face recognition. The concept is illustrated in Fig. 4: to increase generality and thus transferability, the sibling attack employs multi-task learning (MTL). MTL jointly optimizes models solving multiple tasks, in this case two “siblings”: a face recognition model and a face augmented reality (AR) model. Jianping Zhang et al. (2) present the Token Gradient Regularization (TGR) attack on vision transformers (ViTs). TGR reduces the variance of the back-propagated gradient in each internal block of ViTs and utilizes the regularized gradient to generate adversarial samples.
Finally, Zhibo Wang et al. (1) propose the Transferable Targeted Adversarial Attack (TTAA) that operates on class distribution information from both labels and features. In the context of the other works at CVPR ’23, the TTAA paper may feel like an attack that works, but is a bit generic, it is difficult to pinpoint its uniqueness. This is certainly not the fault of the authors: bearing in mind the post-CVPR ’22 state of the art, the fact that it is transferable and targeted would be unique enough. The authors couldn’t have anticipated that targeted transferable attacks would be a major AI security category at CVPR ’23. TTAA is still a paper presenting a high-quality attack that will certainly find its uses.
List of papers on transferable attacks
- Byun et al.: Introducing Competition To Boost the Transferability of Targeted Adversarial Examples Through Clean Feature Mixup
- Cai et al.: Ensemble-Based Blackbox Attacks on Dense Prediction
- W. Feng et al.: Dynamic Generative Targeted Attacks With Pattern Injection
- H. Huang et al.: T-SEA: Transfer-Based Self-Ensemble Attack on Object Detection
- Liang and Xiao: StyLess: Boosting the Transferability of Adversarial Examples
- Z. Li et al.: Sibling-Attack: Rethinking Transferable Adversarial Attacks Against Face Recognition
- Zhibo Wang et al. (1): Towards Transferable Targeted Adversarial Examples
- Zhipeng Wei et al.: Enhancing the Self-Universality for Transferable Targeted Attacks
- Jianping Zhang et al. (1): Improving the Transferability of Adversarial Samples by Path-Augmented Method
- Jianping Zhang et al. (2): Transferable Adversarial Attacks on Vision Transformers With Token Gradient Regularization
- A. Zhao et al.: Minimizing Maximum Model Discrepancy for Transferable Black-Box Targeted Attacks
Subscribe
Enjoying the blog? Subscribe to receive blog updates, post notifications, and monthly post summaries by e-mail.