Privacy attacks @ CVPR ’23: How to steal models and data
Introduction to privacy attacks
There are two topics to go in the AI security @ CVPR ’23 post series (almost there!), and the one I’m covering today is privacy attacks. Privacy is a coveted property of any trustworthy computer system, and AI powered systems are no exception. Building modern AI models needs a lot of training data, and we need to protect any sensitive personal information that may be present in the training dataset. Also, building a custom AI model properly takes a lot of time, effort, and money. We might need to assemble, clean, and curate a custom training dataset. The training itself is an iterative process that costs a lot of time and computational resources. An AI model and training data are valuable intellectual property, so there is a good reason for wanting to keep them private. How do we protect the privacy of our AI pipeline, then?
The first necessary layer of defense is solid cybersecurity policy in the classic sense, namely access & network security policies. If the attacker gains unauthorized access to the machine(s) where the models and/or training data reside, they can steal them outright. Or they can flood the model with a lot of data. If the model happily returns an unrestricted number of outputs, what’s preventing the attacker from using the outputs to train a similarly-performing model very easily?
However, even if the cybersecurity policy is solid, AI models themselves are vulnerable to privacy attacks that can steal the data or the model. CVPR ’23 has seen 9 papers on the topic of privacy attacks & defense, so let’s dive right in.
Model inversion attacks
A popular misconception, even among AI practitioners, is that models inherently protect data privacy. After all, a trained model’s parameters do not directly “display” the data. Also, AI models, especially deep nets, are black boxes. Therefore, the training data is safe if the attacker does not have direct access to it, right? Think again. A model inversion attack can simply “invert the gradient” of the model: start with dummy data and iteratively adapt them to the gradient to minimize the loss. Once the loss is minimal, the “dummy” data closely resembles the actual data. This way, we can for example recover the face of an authorized person from a face recognition model. Model inversion is a powerful idea which enjoys continuous research attention.

The first layer of defense against classic model inversion attacks is the aforementioned good cybersecurity policy, i.e., simply not sharing the model. This prevents the attacker from accessing the gradients. However, CVPR ’22 has shown that black-box model inversion is possible even with hard labels. Last year’s state-of-the-art attack, BREP-MI, uses a GAN and systematically probes the target model until the GAN starts generating relevant images. If you are interested in more details, I have covered BREP-MI in my post on model inversion at CVPR ’22. The RLB-MI attack by Han et al. builds on BREP-MI and engages a reinforcement learning model to improve the systematic probing. This greatly expedites the initial phase when the attack is trying to find examples with positive labels. Fig. 1 showcases RLB-MI’s results, demonstrating the faithfulness of the reconstructed data.
Nguyen et al. study model inversion attacks from a broader, general perspective. They identify two aspects plaguing model inversion attacks in general, and propose a remedy for each:
- Suboptimal identity loss. To reconstruct data, model inversion attacks mostly use an identity loss that penalizes wrong class labels of the inverted data, i.e., when the model classifies the inverted data into another class than the target. Nguyen et al. claim this is insufficient. The objective is to generate data closely resembling actual training samples, rather than any data labeled with the correct class. Therefore, it may be better to calculate the identity loss on the logits instead of class labels.
- Model inversion “overfitting”. Instead of focusing on the semantics of the data, model inversion attacks adapt too closely to random aspects of the target models, such as random variation and noise learned from training data. To remedy this, Nguyen et al. propose using knowledge distillation with the target model as the teacher, the output model as the student, and using a public dataset.

One of the popular machine learning subdisciplines that aims to protect data privacy is federated learning (FedL). FedL is a form of distributed learning operating in a server-worker setting. Workers train local models on private datasets and communicate their model parameters with the server. The server aggregates worker models and disseminates the aggregates to the workers that then start the next round. The workers never send any data over the network directly, which prevents man-in-the-middle attacks. However, much like other ML models, FedL models are susceptible to model inversion too. As a defense, FedL models have started to employ more secure protocols. One example of such protocol is FedMD. In FedMD, workers train on private and public data, but they communicate with the server exclusively about the information related to public data. This sounds secure, but actually isn’t. Takahashi et al. show that FedMD can be breached and indeed, they can infer private data from public-data communication. Their paired-logits inversion (PLI) attack does not require worker model gradients, instead exploiting the confidence gap between the worker and server model performance on public data. Fig. 2 showcases the remarkable results of PLI.
J. Zhao et al. improve another successful attack on FedL, namely the linear layer leakage attack (LLLA). LLLAs insert fully connected layers into the models communicated by the server, which then allow scraping the data that passes through the model. J. Zhao et al. note the poor scalability of LLLAs with respect to dataset and batch sizes. By introducing sparsity and attacking multiple workers at once, they have been able to greatly improve the performance of LLLAs.
Defending data privacy
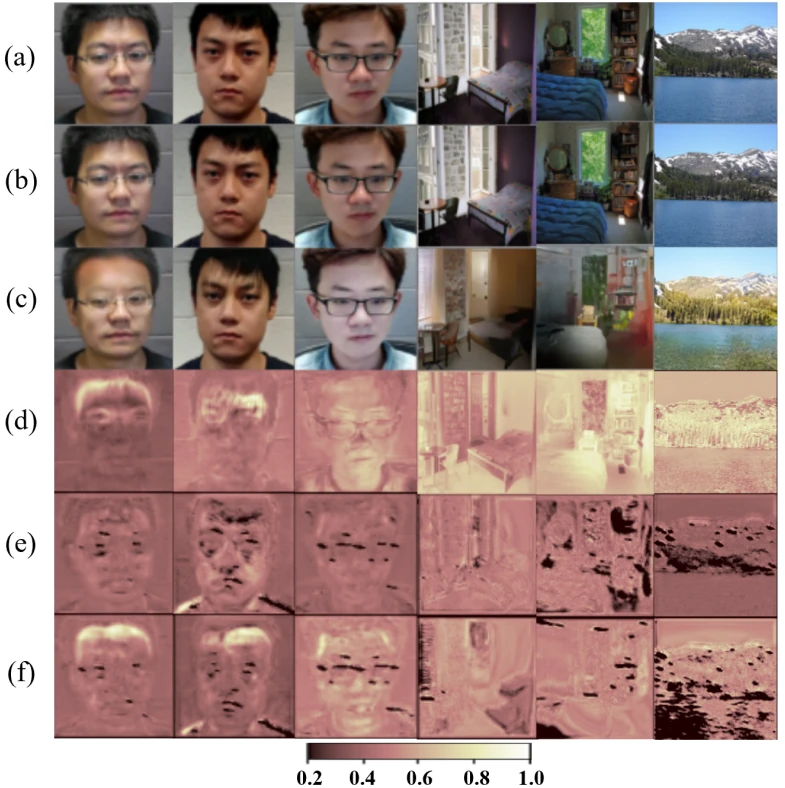
One of possible defense techniques against model inversion is using privacy-preserving features (PPFs). PPFs are image representations designed to enable visual recognition on the one hand and prevent reconstruction into the original data on the other. Zhibo Wang et al. (2) introduce adversarial features-based privacy protection (AdvFace). AdvFace uses a surrogate image reconstruction model that it tries to “break” whilst maintaining as much of the performance on the face recognition task as possible. Fig. 3 demonstrates AdvFace’s success even on images other methods fail to protect. Furthermore, AdvFace has two distinct advantages. Firstly, it is universal, making no assumptions on the methods used by the attacker. Secondly, it is modular, it can be “plugged into” a face recognition model without changing the model.

Another important privacy-related AI topic is unlearning: erasing the influence of selected training examples on the model as if the model has never trained on them. Unlearning is useful to AI practitioners whenever some training examples become invalid. Instead of having to retrain the whole model from scratch, which is often expensive, we just unlearn the selected examples. There are many good reasons training examples become invalid. For example, the data may become outdated. Or a backdoor attack has been discovered in the training data, unlearning those training examples could therefore remove the backdoor. Alternatively, the user invokes their right to be forgotten, which will likely soon become a legal requirement at least in Europe. The last example directly connects unlearning to privacy: an unlearned example is by definition protected.
M. Chen et al. focus on unlearning an entire class, which is useful for e.g., face recognition. They note that meticulous parameter scrubbing across the entire model can be prohibitively expensive, so they propose a more efficient alternative: boundary shifting to match decision boundaries to what would be the fully-retrained model without the unlearned data. Boundary shifting performs neighborhood search to guide the boundaries of the remaining classes into the territory previously occupied by the unlearned class.
Sadasivan et al. take a different definition of unlearnability: protecting the data such that they cannot be used for training in the first place, i.e., the data itself is “unlearnable”. Traditionally, this is accomplished by adding noise to the data such that the model learns the noise instead of the actual data. Sadasivan et al. note that adversarial training “dissolves” the noise produced by existing approaches. After all, adversarial training is by design well-equipped to make the model robust to small noise perturbations. To combat this weakness, Sadasivan et al. introduce the convolution-based unlearnable dataset method that randomly generates convolutional filters using a private key. Class-wise controlled convolutions then add small noise to the data, evading scrubbing by adversarial training.
Steal this model!
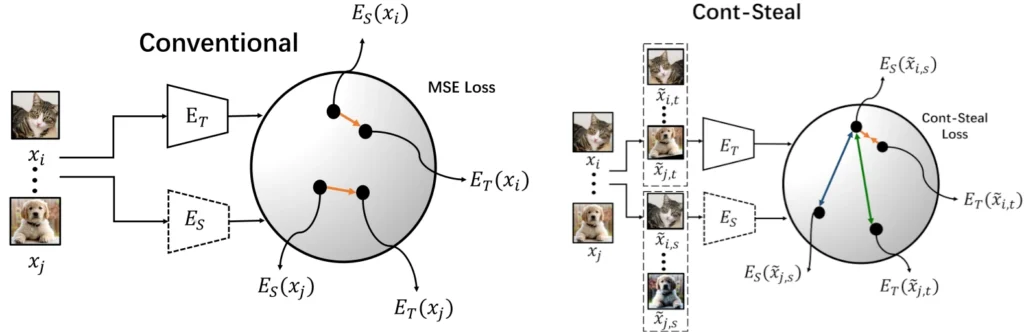
Finally, attackers can steal entire models with model stealing attacks. Model stealing attacks generally involve a surrogate model that is iteratively shaped into the likeness of the target model. To succeed, the attacker probes the target model to elicit key information, and the challenge for the attacker is to minimize the number of probe queries. Sha et al. present Cont-Steal, a contrastive-learning-based attack on encoders. Encoders are used in self-supervised learning pipelines to drastically improve performance on downstream tasks. Encoders notoriously take a lot of time and resources to train, and are therefore juicy targets for model stealing. Fig. 4 illustrates the contribution of Cont-Steal: instead of conventionally pushing the encodings of individual public-dataset images towards the target encoder, Cont-Steal augments the images and operates on a pair-wise loss, improving the performance.
There are several defense tactics against model stealing. One of them is passporting: inserting passport layer(s) into the model that ensure the model only works when a private key—the passport—is input. If it isn’t, the performance of the model degrades significantly. Moreover, having access to the passport can be viewed as a certificate of ownership. Sounds good, but it is not impenetrable. Y. Chen et al. present an ambiguity attack on model passports, generating a substitute passport that guarantees good performance of the model (within 2% of its maximum potential) whilst requiring access to 10% of the training data. The substitute passport is optimized to be clearly distinct from the true passport, which gives the attacker a reasonable proof of ownership.
List of papers
- M. Chen et al.: Boundary Unlearning: Rapid Forgetting of Deep Networks via Shifting the Decision Boundary
- Y. Chen et al.: Effective Ambiguity Attack Against Passport-based DNN Intellectual Property Protection Schemes through Fully Connected Layer Substitution
- Han et al.: Reinforcement Learning-Based Black-Box Model Inversion Attacks
- Nguyen et al.: Re-Thinking Model Inversion Attacks Against Deep Neural Networks
- Sadasivan et al.: CUDA: Convolution-Based Unlearnable Datasets
- Sha et al.: Can’t Steal? Cont-Steal! Contrastive Stealing Attacks Against Image Encoders
- Takahashi et al.: Breaching FedMD: Image Recovery via Paired-Logits Inversion Attack
- Zhibo Wang et al. (2): Privacy-Preserving Adversarial Facial Features
- J. Zhao et al.: The Resource Problem of Using Linear Layer Leakage Attack in Federated Learning
Subscribe
Enjoying the blog? Subscribe to receive blog updates, post notifications, and monthly post summaries by e-mail.