From “maybe” to “absolutely sure”: Certifiable security at CVPR ’23
Introduction
Today, we close the adversarial defense part of the AI security @ CVPR ’23 series with certifiable security (CS). Certifiable security means we can guarantee success against certain attacks, that there is simply no possibility of them succeeding. Security guarantees are of course highly desirable, one can sleep more soundly knowing there isn’t a tiniest sliver of possibility that their AI model will fall prey to an attack. For some applications, e.g., in aerospace engineering or medical robotics, such a guarantee is even required for stakeholders to even consider deploying an AI model in the first place. The motivation to research & develop certifiably secure AI models is therefore high.
However, guaranteeing model security is far from easy. As we have seen in the post summarizing CVPR ’22 work on certifiable security, there are a number of limitations. Firstly, only a small fraction of possible attack vectors can be covered by CS methods. Secondly, even though we have seen some improvements at CVPR ’22, CS methods are much slower than their non-certified counterparts. Finally, CS methods have sacrifice a considerable portion of their accuracy on clean data. All in all, there is a steep performance price to pay for the guarantee, if a guarantee is available in the first place.
At CVPR ’23, we have seen 3 papers whose topic revolves around certifiable security. They are quite topically diverse, unlocking certifiable security approaches in areas where none were available previously. So let’s dig in!
Strike first, strike hard
One of the key principles of security and indeed, classic strategy in general, is that the actor who strikes first has the advantage. The first striker chooses when, where, and how an action takes place, the other party merely reacts. Frosio & Kautz observe that in AI security, it is the adversarial attacker who has the advantage. The attackers craft the attacks and deploy them as they see fit, whereas the AI model simply waits for inputs. Can defenders grab the advantage from the attackers? If so, how?

Frosio & Kautz propose defensive data augmentation. Their A5 (Adversarial Augmentation Against Adversarial Attacks) framework optimizes and adds a friendly defensive perturbation to the data. The defensive augmentation is performed at several stages during the flow from raw data to our protected AI model, as shown in Fig. 1. If we prevent the attacker access to the original data and expose only the defensively-augmented dataset, we take the first strike advantage from the attacker.
The defensive perturbations ensure that adversarial perturbations with [/latex]\epsilon[/latex] (perturbation magnitude) up to a certain threshold cannot manipulate the model. A5 offers a number of robustification strategies: an offline (O) strategy useful for theoretical purposes, a practical robustifier model (R) strategy that trains a deep net model to output defensive perturbations, and a robustifier + classifier retraining (RC) strategy that retrains the protected AI model (classifier) in addition to training the robustifier. From the authors’ experience, the R strategy does not modify the original model, whereas the RC strategy is more efficient. All A5 strategies confine the defensively-augmented inputs into certified-robust CROWN-IBP bounds (Zhang et al., ICLR ’20). These bounds are computed using auto_LiRPA (Xu et al., ICLR ’21). This is where A5 gets its “certified defense” label.

Another key aspect of the paper is that A5 works against physical attacks through the final physical (P) strategy. As its defensive perturbation, the P strategy optimizes defensive shape changes of the physical object that preempt an adversarial attack. This makes the A5 paper the first certifiable security method against physical adversarial attacks, which is a significant contribution. As an example task to demonstrate this, the authors have selected optical character recognition (OCR). Fig. 2 shows how to robustify letters such that signs containing the “robust font” are robust to \(l_\infty\)-norm attacks with magnitude of \(\epsilon \leq 0.1\). This is a very solid defense—an attack with \(\epsilon = 0.1\) is already quite brutal, perturbing each pixel by up to ~25 intensity steps on the classic scale of 1 to 255. Most AI security works operate with \(\epsilon \leq \frac{8}{255} \approx 0.03\), at which point attacks start becoming very conspicuous. As we can see plainly, the robust font is still well legible and the OCR accuracy remains high.
Two sides of one coin
Every once in a while, we are firmly reminded that attacking and defending are two sides of the same coin. Security is a never-ending race of the attackers developing an attack, the defenders developing a defense, the attackers learning about the defense and developing a new attack, and so forth and so forth. B. Wang et al. present an efficient graph neural network (GNN) attack inspired by certifiable security. The authors are therefore on the red team, learning from the efforts done in certifiable security done on GNNs and using the knowledge to their advantage.
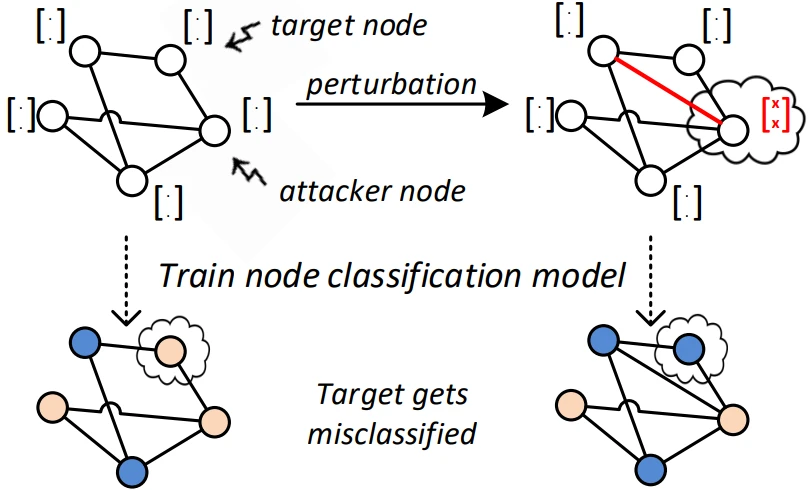
As Fig. 3 illustrates, an adversarial graph perturbation is a small modification of the graph’s structure that results in target nodes or subgraphs being misclassified. Similarly to models operating on other types of data, GNNs can be attacked by poisoning the training data or crafting perturbations submitted for inference at test time. For the improved attack, B. Wang et al. leverage the randomized smoothing to compute certified robustness score for the individual nodes of the graph. The nodes with low certified robustness score are prime targets for an attack, because they require the lowest effort. This is incorporated in a custom attack loss which assigns node weights inversely proportional to the certified robustness. As a result, the method targets the weak nodes with an attack of magnitude just a little greater than the certified robustness. To defend against the attack, B. Wang et al. propose to use adversarial training, but they note that on its own it might not be sufficient. And so the attack-defense-attack-defense cycle continues…
Flying on a cloud safely
This week’s final paper by Jinghuai Zhang et al. introduces certifiable security to point cloud classification. Point cloud recognition and classification are crucially important for many important AI applications such as autonomous driving and augmented reality. Unsurprisingly, point cloud models are susceptible to adversarial attacks too. Fig. 4 illustrates how adversarial clouds can distort the 3D structure of a point cloud. So, let’s see how to certify point cloud classification security.

Jinghuai Zhang et al. propose PointCert, a method that employs a divide and conquer strategy, somewhat similar to randomized smoothing. They propose to split the point cloud into several disjoint subclouds, i.e., each point belongs to exactly one subcloud. As the splitting method, PointCert uses cryptographic hashing, namely MD5, which has uniform random output. Based on the hash value, each point is therefore uniformly randomly assigned to a subcloud. This approach deliberately avoids assigning points to subclouds based on their distance to each other. We need to split a single point cloud into subclouds of roughly the same, but sparser structure. The sparsity also mitigates the negative influence of an adversarially perturbed on its neighborhood. Instead of a single classifier, PointCert uses ensemble classifier on the subclouds to reach its decision. The authors show that PointCert is certifiably secure up to a certain exact number of perturbed points, which can be exactly calculated from the point cloud and subcloud parameters. In practice, PointCert maintains high accuracy on roughly up to 100-200 perturbed points in a point cloud of size 10000.
List of papers
- Frosio & Kautz: The Best Defense Is a Good Offense: Adversarial Augmentation Against Adversarial Attacks
- B. Wang et al.: Turning Strengths Into Weaknesses: A Certified Robustness Inspired Attack Framework Against Graph Neural Networks
- Jinghuai Zhang et al.: PointCert: Point Cloud Classification With Deterministic Certified Robustness Guarantees
Subscribe
Enjoying the blog? Subscribe to receive blog updates, post notifications, and monthly post summaries by e-mail.