Backdoor attacks & defense @ CVPR ’23: How to build and burn Trojan horses
Introduction
Previous posts on AI security research at CVPR ’23 revolved around adversarial attacks. Adversarial attacks are inference-time (or test-time attacks): they attack a trained, fully-fledged model with manipulated data. Another possible approach is to poison the model during training. These train-time attacks are called backdoor attacks (sometimes also Trojan attacks). As their name suggests, they implant a backdoor in the trained model that, when triggered later, manipulates the model according to the attacker’s wishes. To implant a backdoor in vision models, backdoor attacks add a set of manipulated images to the attacked model’s training dataset. These images teach the model to react to a certain trigger in the image in a way favorable to the attacker, regardless of the actual image content. For example, a backdoor in a face recognition model may result in the attacker being able to authenticate anyone they want as the Chief Security Officer.
The attackers generally optimize two criteria. The first is that the trigger works reliably. The second is stealth. Stealth in the context of backdoor attacks has three dimensions:
- The triggers should be visually inconspicuous to evade detection by human eyes.
- The amount of poisoned data added to the training set should be minimal.
- The backdoored model should work reliably on non-triggered inputs to minimize suspicion about the model’s performance.
In other words, the attackers want to prevent the defenders (model owner) from figuring out something is wrong with their model and/or training pipeline. Conversely, the defenders want to ensure the model does not contain any backdoors.
Backdoor attacks are a serious AI security threat. Firstly, they give the attacker permanent keys to the model: once the backdoor is there, the attackers can trigger it reliably any time they want. Secondly, modern backdoor attacks require a small amount of poisoned data, <5% is a safe figure to quote, with some attacks only requiring 0.5-1%. Thirdly, modern triggers are outright invisible. Classic techniques such as perturbations, patches, or image blending are making way to imperceptible techniques that e.g., slightly perturb frequency. There are 15 papers on backdoor attacks and defense at CVPR ’23 in total, summarized in this blog post.
New backdoor attacks
Let’s start on the red team. Jiang et al. broaden the set of trigger domains by introducing a color space backdoor attack. They utilize particle swarm optimization penalized for naturalness (to avoid garish color shifts) to find the color shift trigger. Their experiments show that the trigger is reliable, and Fig. 1 demonstrates the stealth of the attack.

Vision transformers (ViTs) are the state of the art in a number of computer vision tasks, including image classification, so they are a prime target for backdoors. Yuan et al. present a comparative study that highlights the differences in backdoor behavior between ViTs and classic CNNs. Turns out ViTs are resilient against image-blending-based triggers, but are vulnerable to patch-based attacks. This aligns with the way ViTs naturally operate: they slice an image into patch tokens, after all. The BadViT attack proposed in this paper is therefore patch-based. Zheng et al. researched the same topic, coming up with TrojViT, an attack that leverages patch saliency information, attacking the patches that the model pays the most attention to. On the generative models front, diffusion models have started to gain traction. They need defense too: backdoored diffusion models can ruin the quality of the downstream tasks or outright generate inappropriate content. There were 2 backdoor attacks on diffusion models: TrojDiff by W. Chen et al. and BadDiffusion by Chou et al. TrojDiff is universal, attacking both DDPM and DDIM models, BadDiffusion attacks only DDPM models, but boasts low poisoning rate required for the backdoor to work: less than 5% of the training data. Finally, Yu Yi et al. contribute a backdoor attack on deep image compression.
Backdoor attacks generally aim to manipulate AI model outputs, but there’s another way to sabotage a model: denial of service (DoS) attacks. Many models have the same(ish) inference time for arbitrary valid inputs, but there are models with inference time dependent on the input. Inputs manipulated to bloat inference time can clog the model and make it unusable. S. Chen et al. present a DoS attack on early-exit dynamic neural networks (DyNNs). DyNNs feature a number of exit points along the pipeline from input to full output. The exit points are used if the DyNN has enough information to make its output decision based on the information processed up to said exit point. The idea is that most images require a fraction of the computational power of a contemporary deep net, so we only use the full deep architecture for the difficult inputs and exit early for the more “simple” images. The DoS attack presented in this paper is optimized to make a difficult case out of each triggered image.
Defending backdoor attacks in training
Let’s move over to the blue team and see how we can defend against backdoor attacks. One of the surprising conclusions I drew from reading the CVPR ’23 work on the topic is that backdoor defense at training time relates closely to self-supervised learning (SSL). Our training dataset is potentially poisoned, and we do not know which items are clean and which are poisoned. Since we do not know what data to trust, we treat the whole training dataset as unsupervised poisoned data. This allows us to leverage the semantic information in the content, but not get fooled by the trigger labels. We initialize a supervised clean dataset to a handful of guaranteed-clean images. Then, we train the model as an SSL model, iteratively enlarging the clean dataset based on the information gleaned from the model at each round. After a sufficient number of rounds, the vast majority of the actually clean images are in the clean supervised dataset, whilst the poisoned images remain in the unsupervised data. This allows us to train a well-performing classifier. This approach seems to be the common ground of a number of CVPR ’23 works.

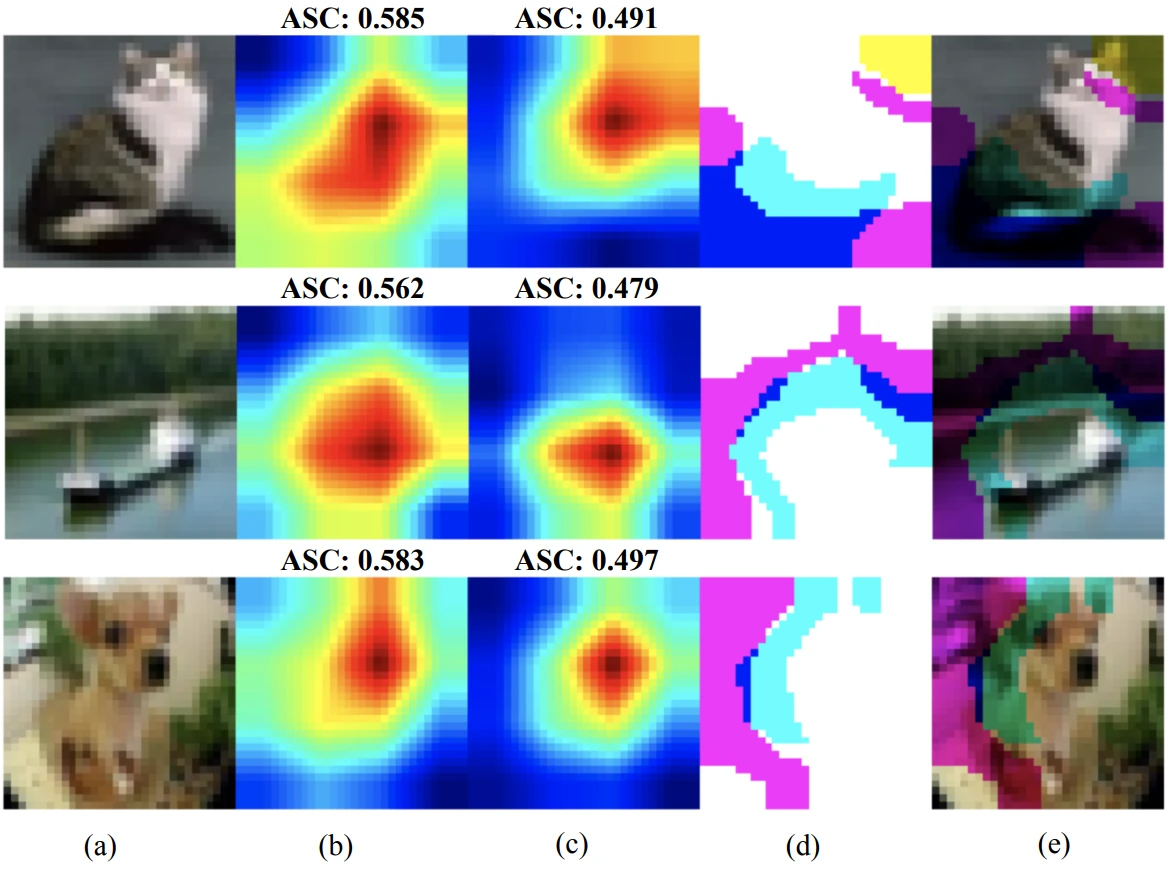
Gao et al. propose adaptive splitting defense, which ranks the images in each round based on the L1 loss: their method adds the images with the lowest L1 loss to the clean dataset. Tejankar et al. cluster image representations coming from the model using k-means, using the cluster centroid information as supervised labels. Then they feed the labels to GradCAM to find salient suspicious patches. Fig. 2 shows an example of top- and bottom-ranked images found this way. Moreover, Tejankar et al. observe that clustering the representations this way usually puts the triggered images in one cluster. S. Feng et al. make the same observation and leverage it to remove backdoors from third-party encoders, which are very useful in SSL to slash computational and other costs. Finally, Mu et al. show that adversarial and backdoor attacks are connected vessels: an untargeted adversarial attack on a backdoored model highly likely flips the image class to the target class of the backdoor (see Fig. 3). To iteratively update the clean data pool, Mu et al. essentially utilize adversarial training: each round, they adversarially train the model using attacks on the clean data. Then, they add the images with the least output discrepancy between the original and adversarially-trained model to the clean dataset.

There are also other defense strategies beyond the SSL-like scenario. Pang et al. use knowledge distillation. The potentially backdoored model trained on the suspicious training dataset is the teacher, the output backdoor-free model is the student. Instead of the training dataset, the knowledge distillation operates on an extra dataset containing unlabeled and possibly out-of-distribution data. The student therefore aims to mimic the teacher’s output on data that wasn’t used to train—and possibly backdoor—the original model. The student model therefore gains (a considerable part of) the teacher’s semantic prowess whilst not copying any present backdoors. Finally, Z. Zhang et al. propose to extract causal information from the potentially poisoned training data. They argue that backdoor attacks do not use causal information, yet causal reasoning is crucial for semantic inference. Replacing the original poisoned images with their causal representation therefore removes the trigger.
Last line of defense
The last line of defense against backdoor attacks is to detect that a model is backdoored at test-time. It is preferable to know about a backdoor earlier, but at this stage at least we can pull the model out of production to minimize the damage. One of the classic strategies is trigger inversion: given a possibly backdoored model, trigger inversion synthesizes a trigger that is able to reliably flip the output. If the inverted trigger looks like random noise, the model is probably clean—essentially, we need an adversarial perturbation to flip classes. However, if the inverted trigger takes a constrained, distinct shape, then there is likely a backdoor in the model. Sun & Kolter present SmoothInv, a method that first constructs a robust smoothed version of the tested model which then guides synthesis of the trigger. The advantage of the method is automatic detection of the trigger target class.

Trigger inversion assumes that we have complete information about the model. But what if we operate a model trained by someone else? Can we do black-box backdoor defense with only hard labels being output from the model, not even confidence scores? X. Liu et al. say we can, with their test-time corruption robustness consistency evaluation (TeCo). Essentially, TeCo leverages image corruption to create image probes that extract robustness information from the model. If we corrupt clean images, the outputs will be consistent w.r.t. robustness. However, if we have a backdoored model and we corrupt triggered images, the output robustness consistency will vary wildly. TeCo operates in a difficult setting, and its currently quite taxing computationally. Nevertheless, unlocking black-box backdoor defense is certainly interesting.
List of papers
- S. Chen et al.: The Dark Side of Dynamic Routing Neural Networks: Towards Efficiency Backdoor Injection
- W. Chen et al.: TrojDiff: Trojan Attacks on Diffusion Models With Diverse Targets
- Chou et al.: How to Backdoor Diffusion Models?
- S. Feng et al.: Detecting Backdoors in Pre-Trained Encoders
- Gao et al.: Backdoor Defense via Adaptively Splitting Poisoned Dataset
- Jiang et al.: Color Backdoor: A Robust Poisoning Attack in Color Space
- X. Liu et al.: Detecting Backdoors During the Inference Stage Based on Corruption Robustness Consistency
- Mu et al.: Progressive Backdoor Erasing via Connecting Backdoor and Adversarial Attacks
- Pang et al.: Backdoor Cleansing With Unlabeled Data
- Sun & Kolter: Single Image Backdoor Inversion via Robust Smoothed Classifiers
- Tejankar et al.: Defending Against Patch-Based Backdoor Attacks on Self-Supervised Learning
- Yu Yi et al.: Backdoor Attacks Against Deep Image Compression via Adaptive Frequency Trigger
- Yuan et al.: You Are Catching My Attention: Are Vision Transformers Bad Learners Under Backdoor Attacks?
- Z. Zhang et al.: Backdoor Defense via Deconfounded Representation Learning
- Zheng et al.: TrojViT: Trojan Insertion in Vision Transformers
Subscribe
Enjoying the blog? Subscribe to receive blog updates, post notifications, and monthly post summaries by e-mail.