
Reality can be lying: Deepfakes and image manipulation @ CVPR ’23
Introduction
The final topic to cover in the AI security @ CVPR ’23 series is deepfakes & image manipulation. Nowadays, it is cheap and easy to stealthily, yet convincingly manipulate existing images or create new AI-generated fake images, called deepfakes, from scratch. The success of image manipulation & deepfakes is clearly demonstrated by the mental paradigm shift in admitting visual information as evidence. The barrage of fake speeches by world leaders, fake celebrity pornography, or even “live” chatbots has rightfully made us skeptical. But just being skeptical is not a long-term solution. It is crucial that the security community can detect deepfakes & image manipulation.
Similarly to other areas in security research, deepfakes & image manipulation research is a coin with two sides. One side of the coin is covered by the blue team that improves the defense provided by detection models. The red team is on the other side of the coin, researching novel attack techniques to fool the detection models. The red team gives the blue team new impulse for improvement, the blue team brings new challenges for the red team to crack. There are 4 papers on deepfakes & image manipulation at CVPR ’23, two “blue” and two “red”.
Defending against deepfakes & manipulations
Let’s start on the blue team. Guo et al. present a state-of-the-art deepfake & image manipulation detection (DIMD) model, Hifi-Net. Hifi-Net nicely demonstrates the classic DIMD pipeline. An DIMD model takes an image as the input and outputs two pieces of information. Firstly, a binary label indicating whether the image is real or fake. Secondly, the fakeness map covering the input image and indicating which parts of the image are fake according to the model. Fig. 1 illustrates a continuous fakeness map that scores the pixels between 0 (not manipulated) to 1 (fully manipulated). The main contribution of HiFi-Net is multi-level manipulation detection: the model features a number of branches, each detecting a different kind of manipulation. This gives finer insight into the manipulation techniques the attacker had used than a mere binary indicator and an abstract fakeness map. HiFi-Net can discern between 13 types of deepfakes & manipulations, as summarized in Figure 2. To facilitate further research on fine-grained DIMD, Guo et al. contribute the HiFi-IFDL dataset.
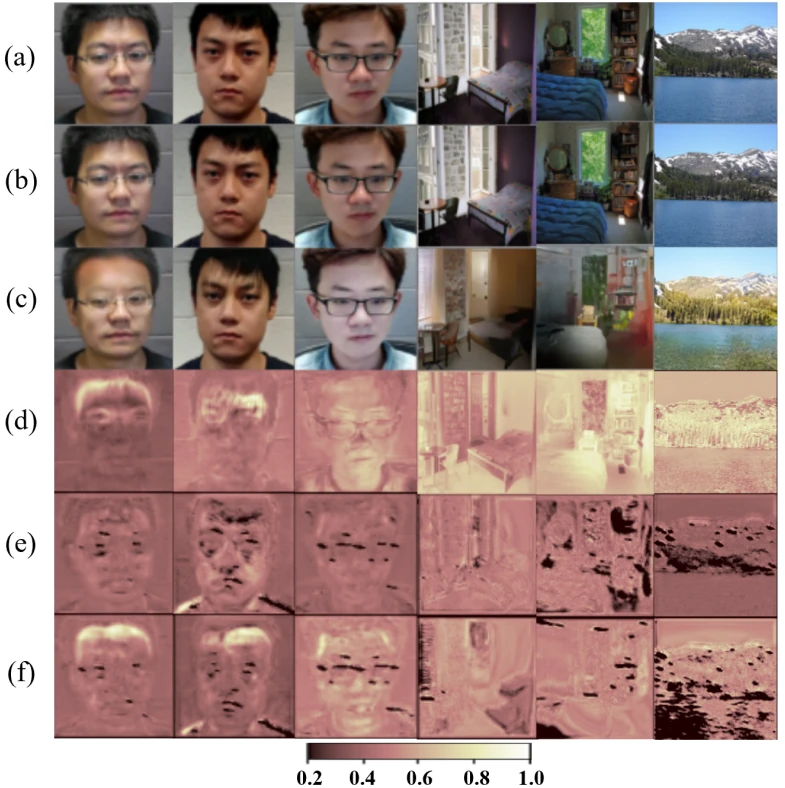
Asnani et al. note that the main challenge of existing DIMD models is poor generalization: DIMD models fail to detect manipulation & deepfake methods they have not seen during training. Asnani et al. identify the passive nature of DIMD as the culprit, in the sense that the DIMD pipeline simply waits for the attackers to make their move. Since the attackers have infinite possibilities to tamper with the image, they will always have a massive advantage and the passive DIMD pipeline therefore cannot guarantee success. Instead, Asnani et al. prefer a proactive scheme: each image that we want to protect is first encrypted with a template, a perturbation added to the image that enables DIMD and is invisible to preserve content quality. Only then we release the image to the public. If we later want to determine whether a protected image has been tampered with, we check the integrity of the template. Asnani et al. contribute a method that allows unsupervised optimization of the templates, enabling proactive manipulation & detection protection without making the templates too trivial. This means that the attacker does not have a simple way to re-add the template after the manipulation. Fig. 1 shows that the proactive method pinpoints the actual manipulations more accurately than the passive pipeline.

Attacking the watchdogs
Now, let’s move over to the red team and try to fool DIMD models. DIMD models are AI models, and therefore they too are susceptible to adversarial attacks. And much like in the broader adversarial attack research community, there is great interest in black-box and transferable attacks on DIMD models. Hou et al. exploit the adversarial weakness of DIMD models and contribute a new adversarial-attack-based method, StatAttack. To detect manipulations & fakes, DIMD models look at the statistical difference between known real and fake images. Hou et al. leverage exposure, blur, and noise as statistically-sensitive image properties to craft the adversarial attacks. Then, StatAttack uses a custom distribution-based loss that brings the distribution of the fake attack images even closer to the real images. In addition to vanilla StatAttack, the authors present a more expensive MStatAttack variant that performs multilayer perturbation of the original image. Figure 3 showcases the successful attack images generated by (M)StatAttack, side-by-side with existing state of the art (VMIFGSM) and the original image.

Shamshad et al. add customizability to deepfake & image manipulation attacks. Existing adversarial-attack-based methods perform a non-semantic search for the minimal perturbation that pushes the image across a decision boundary. This adds unpredictable noise to the image, which likely doesn’t have any meaning. Shamshad et al. propose attribute-constrained attacks that allow the attacker to guide the search for an attacked image semantically. For example, “give this person blonde hair” or “change the eye color”. The attacker can either use image-based constraining, transferring facial characteristics from the given image, or text-based constraining, by providing a text prompt. Fig. 4 shows that the resulting attack is very stealthy, compared to existing PGD methods. It should be noted that the PGD attack in Fig. 4 with \(\epsilon = 0.06 \approx \frac{15}{255}\) can be considered a very strong perturbation. Classic adversarial attacks are often able to succeed with \(\epsilon \leq \frac{8}{255}\). Nevertheless, the attribute-constrained attacks clearly offer a strong, versatile attack against DIMD models.

List of papers
- Asnani et al.: MaLP: Manipulation Localization Using a Proactive Scheme
- Guo et al.: Hierarchical Fine-Grained Image Forgery Detection and Localization
- Hou et al.: Evading DeepFake Detectors via Adversarial Statistical Consistency
- Shamshad et al.: Evading Forensic Classifiers With Attribute-Conditioned Adversarial Faces
Subscribe
Enjoying the blog? Subscribe to receive blog updates, post notifications, and monthly post summaries by e-mail.





