
AI security @ CVPR ’22: Non-classic adversarial attacks research
This post is a part of the AI security at CVPR ’22 series.
“Non-classic” adversarial attacks
One of the most interesting aspects of cybersecurity is the diversity of attack vectors, or paths through which an attack can succeed. Perhaps you should have updated your critical component to patch 14.7.0895 to avoid 14.7.0894’s critical security issue. Maybe an attacker sniffs your weakly-encrypted packets over the network. Or they have “casually” befriended your system administrator in World of Warcraft… The attacks range from exploitation of obscure bugs to James-Bond-like plots with high tech gadgets. It’s exhilarating, and one of my personal reasons for pivoting from pure AI to AI security.
How diverse are attacks on computer vision models? Not as diverse as in classic cybersecurity, but enough to be interesting. In a previous post, I have introduced the “classic” label for adversarial attacks. A classic attack targets models that take 2D images as inputs and solve classification, detection or segmentation tasks. The attack uses an adversarial pixel perturbation of an input image, which is either optimized directly (white-box attacks) or on surrogate models trained once we elicit enough training data from the target (black-box attacks). In this context, a “non-classic” attack is an attack that subverts this pipeline in at least one way: takes outputs other than 2D images, does not attack through perturbation, or targets a different task.
There are 15 papers on non-classic attacks, you can find the full list at the bottom of this post. Below I summarize them categorized by the main way they subvert the classic pipeline.
Unconventional attack vectors
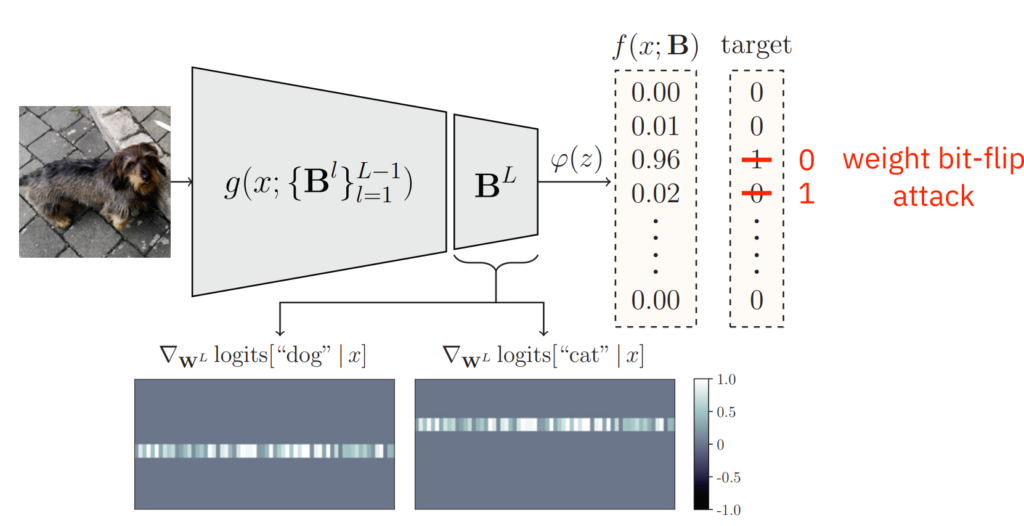
Let’s start with works on attacks that do something else than adversarial pixel perturbation. The stand-out to me is the paper by Özdenizci et al. on the topic of weight bit-flip attacks. These attacks are fault-injection attacks that simply flip sensitive bits in the memory where the target model is stored to manipulate the model. In principle, any part of the model can be attacked, including the weights (hence the name), but an especially juicy target are the outputs, as illustrated in Fig. 1. Those are in the vast majority of classifiers one-hot encoded: the vector’s coordinates correspond to individual classes, exactly one coordinate is equal to 1 (the assigned class), all others are 0. Simply flipping two bits can therefore reclassify an image. The attacker does not need to know the architecture or specifics of the model, only where the “juicy” bits are stored in the memory. Özdenizci et al. propose to defend against this type of attack by outputting custom bit strings encoding semantic similarity between classes instead of one-hot vectors. This way, flipping arbitrary bits may more easily result in invalid codes that notify the model owner of an attack.
The remaining two papers in this category both perform a variant of the adversarial perturbation attack, but with a twist. Chen et al. attack image captioning models that generate a content-describing caption for a given image. The authors argue that due to the open-ended, Markov-process nature of the task, it is difficult to forge an input to elicit a particular target output. Instead, their NICGSlowDown attack is essentially a denial-of-service attack: inputs are forged to dramatically increase inference time. The authors report an increase of up to 483%. Thapar et al. propose to hybridize adversarial attacks on video deep net models: instead of using just the classic pixel perturbations, they introduce video frame rotations and show the efficacy of attacks that combine both.
Non-2D image inputs

Now, onwards to attacks on non-2D image inputs. Three papers concern attacks on 3D point clouds, structures crucial for 3D perception of computer vision models. There are a number of security-critical applications where it is important for 3D scene perception to be undistorted, including autonomous driving, aerospace engineering, or medical robotics. As we see from Fig. 2, existing attacks can indeed completely change the model’s perspective. Pérez et al. move towards certifiable defense for 3D cloud applications (I have covered certifiable defense extensively in my previous post). Huang et al. analyze 3D cloud points to find the weakest ones that are the most susceptible to perturbations. This information can be used for white-box and black-box attacks, as well as for defense. Finally, Li et al. provide a new classifier with an in-built constraint optimization method that defends against attacks using implicit gradients. Beyond point clouds, 3D-attack work at CVPR ’22 also involves attacks on stereoscopic images (Berger et al.) and spherical images (Zhang et al.).
Niche tasks

Last, but not least, let’s recap work on attacking tasks other than classification, detection, and segmentation. Gao et al. attack co-salient object detection (depicted in Fig. 3) that aims to track a salient object across a group of images. An attack on this task perturbs a group member target image such that the object is not tracked. This work nicely highlights the shifting morality aspect of security: more often than not, we assume that the attacker is evil and the defender noble. Here, one of the use cases is protecting the attacker’s privacy against voracious defender models that scour the Internet for the attacker’s private information. Gao et al. are the first to devise a black-box co-salient object detection attack.
The work of Schrodi et al. concerns optical flow networks that process image streams, e.g., from a self-driving vehicle’s camera. The main positive takeaway is that as long as the attacker does not have access to the image stream, optical flow networks can be made robust to adversarial attacks. Dong et al. tackle attacks on few-shot learning. Defending a few-shot model is challenging, partly because the model did not have enough training data to capture the finer nuances behind its classes. The authors introduce a generalized adversarial robustness embedding model that contributes to the adversarial loss used to bolster the model’s defenses. Zhou & Patel make metric learning more robust. Finally, Wei et al. contribute to the topic of transferable cross-modal attacks: using image perturbations trained on a surrogate white-box model, they manage to successfully attack video-model targets in a black-box setting.
Overall, CVPR ’22 has seen a content-rich, diverse set of papers that greatly expand the adversarial attack dictionary. Computer vision models can indeed be attacked from various angles, bringing the AI security closer to the amazingly diverse world of classic cybersecurity.
List of papers
- Berger et al.: Stereoscopic Universal Perturbations across Different Architectures and Datasets
- Chen et al.: NICGSlowDown: Evaluating the Efficiency Robustness of Neural Image Caption Generation Models
- Dong et al.: Improving Adversarially Robust Few-Shot Image Classification With Generalizable Representations
- Gao et al.: Can You Spot the Chameleon? Adversarially Camouflaging Images from Co-Salient Object Detection
- Huang et al.: Shape-invariant 3D Adversarial Point Clouds
- Li et al.: Robust Structured Declarative Classifiers for 3D Point Clouds: Defending Adversarial Attacks with Implicit Gradients
- Özdenizci et al.: Improving Robustness Against Stealthy Weight Bit-Flip Attacks by Output Code Matching
- Pérez et al.: 3DeformRS: Certifying Spatial Deformations on Point Clouds
- Ren et al.: Appearance and Structure Aware Robust Deep Visual Graph Matching: Attack, Defense and Beyond
- Schrodi et al.: Towards Understanding Adversarial Robustness of Optical Flow Networks
- Thapar et al.: Merry Go Round: Rotate a Frame and Fool a DNN
- Wang et al.: Bandits for Structure Perturbation-based Black-box Attacks to Graph Neural Networks with Theoretical Guarantees
- Wei et al.: Cross-Modal Transferable Adversarial Attacks from Images to Videos
- Zhang et al.: 360-Attack: Distortion-Aware Perturbations From Perspective-Views
- Zhou & Patel: Enhancing Adversarial Robustness for Deep Metric Learning
Subscribe
Enjoying the blog? Subscribe to receive blog updates, post notifications, and monthly post summaries by e-mail.




