
AI & security @ CVPR ’22: Classic adversarial attacks research
This blog post is a part of the AI & security at CVPR ’22 series. Here I cover the adversarial attack terminology and research on classic adversarial attacks.
Terminology and state of the art

The cornerstone of AI & security research, and indeed the classic CV attack, is the adversarial attack, first presented in the seminal paper Szegedy et al.: Intriguing properties of neural networks (CoRR 2014). The attack, illustrated in Fig. 1, adds noise (called adversarial perturbation) to the original image such that the model’s outcome is different from what we’d normally expect. In addition to successfully fooling the model, the attacker tries to ensure the perturbation is inconspicuous for the attack to evade detection. In Fig. 1 we indeed see that the adversarially perturbed image on the right confuses the model that it is a gibbon, yet it looks like a clean image of a panda to us.
There are two major categorizations used for adversarial attacks. Firstly, targeted vs. untargeted attacks. An untargeted attack succeeds if the adversarial perturbation produces any output different from the true output on the clean image (“it’s not a panda”). A targeted attack succeeds if the resulting output matches the target set by the attacker (“it is specifically a gibbon”). Both targeted and untargeted attacks are achievable by the state of the art. The second categorization is white- vs. black-box attacks. A white-box attack relies on full knowledge of the attacked model, its architecture, and training data used to create it. A black-box attack works without this knowledge. In literature, one can also encounter the term “gray-box attack”, which is used for attacks that know something about the model, but not everything. Unsurprisingly, white-box attacks have much better success rate, but the black-box attacks already have respectable performance as well.
Hand-in-hand with adversarial attacks comes adversarial defense: making the models resilient against adversarial attacks to ensure their secure operation. Most of the time, this takes the form of adversarial training: augmenting the set of training data with adversarial examples labeled with the true label, such that the model learns to ignore the perturbations. Using the running example in Fig. 1, this would involve feeding the adversarial right-most image labeled “panda” to the training set. Note that the objective of adversarial defense is twofold: the models should be robust to adversarial attacks, but at the same time exhibit good performance on their designed task. For example, there is little point to a face verification model that cannot be fooled by adversarial attacks, but naturally makes mistakes 50% of the time. The two objectives can at times be at odds, which may result in catastrophic overfitting: the model tries so hard to be adversarially robust that it loses its generalization capability and massively drops its test accuracy. Obviously, catastrophic overfitting is to be avoided.
Overall, the security implications are clear: if models can be tricked by doctored inputs into producing outputs desired by the attacker, how can we trust their decisions? This motivates active research on the topic and including of adversarial defense strategies to model training in practice.
“Classic” adversarial attacks research
In total, there are 47 papers on adversarial attacks at CVPR ’22. That is a lot, so I decided to sub-categorize further. In this section, I summarize research on what I call “classic” adversarial attacks: the target is a CV model that takes 2D images as input and outputs classification, detection, or segmentation scores/labels. There are 24 papers on classic adversarial attacks, you can find their full list with link at the bottom of this text.
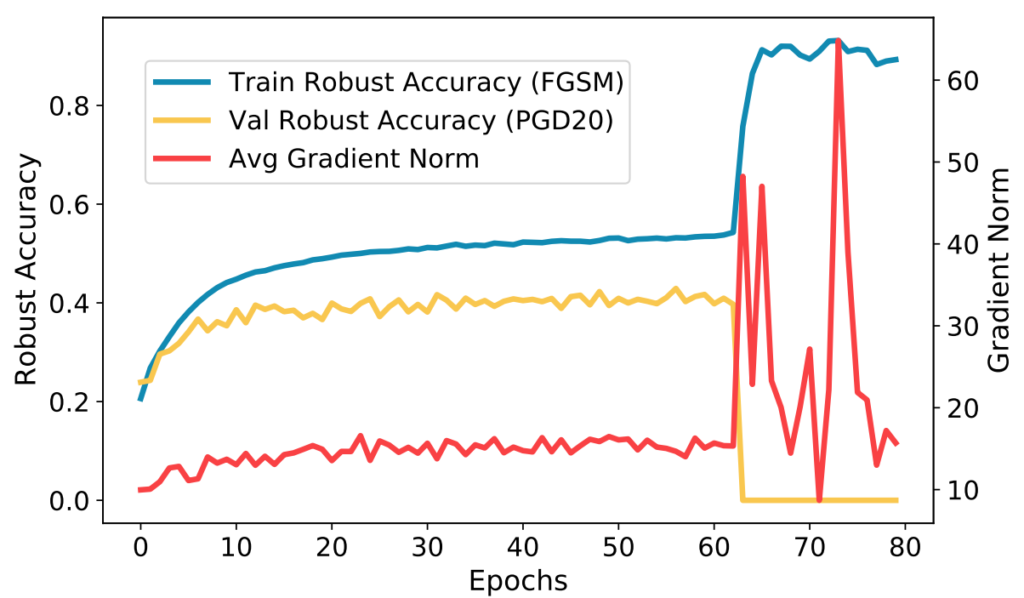
From the fundamental perspective, the stand-out paper is the Frank-Wolfe adversarial training paper by Tsiligkaridis & Roberts. Training modern CV models involves a lot of training data, and adversarial training consequently requires a lot of adversarial training examples. Most state-of-the-art attacks use the iterative PGD optimization, which is slow, so we cannot generate a lot of adversarial examples fast. This makes single-step methods appealing, yet the classic FGSM method makes the model prone to catastrophic overfitting. Using Frank-Wolfe optimization, the authors propose a new method that is shown to generate high-quality adversarial examples fast, which is exactly what is needed for adversarial training. The paper by Li et al. sheds further light on catastrophic overfitting in single-step adversarial training. As Fig. 2 shows, the phenomenon is tied to fluctuations of the gradient norm during training phase. To control the fluctuations, the authors propose to restrict the gradient in a specific subspace.
Many papers focus on transferability of adversarial attacks. It can be quite expensive to devise adversarial perturbations, especially in black-box scenarios. Therefore, it is desirable to be able to use successful adversarial attacks across different models to save resources. The paper that stood out to me was Zero-Query Transfer Attacks on Context-Aware Object Detectors by Cai et al. Their method boasts high success rate on attacking object detectors without having to query the attacked model at all, which greatly increases stealth.
Another interesting group of papers researches different kinds of perturbation. The classic perturbation varies pixel intensity within certain range from the values of the original image. This restriction aims to make the attacks invisible to the human eye, but sometimes, the result is still conspicuous. Yu et al. research the adversarial effect of rain in the context of semantic segmentation. Luo et al. develop frequency-based attacks that are harder to notice than pixel-intensity based perturbations. He et al. combine transferability with sparse attacks that minimize the number of perturbed pixels without restrictions on pixel intensity.
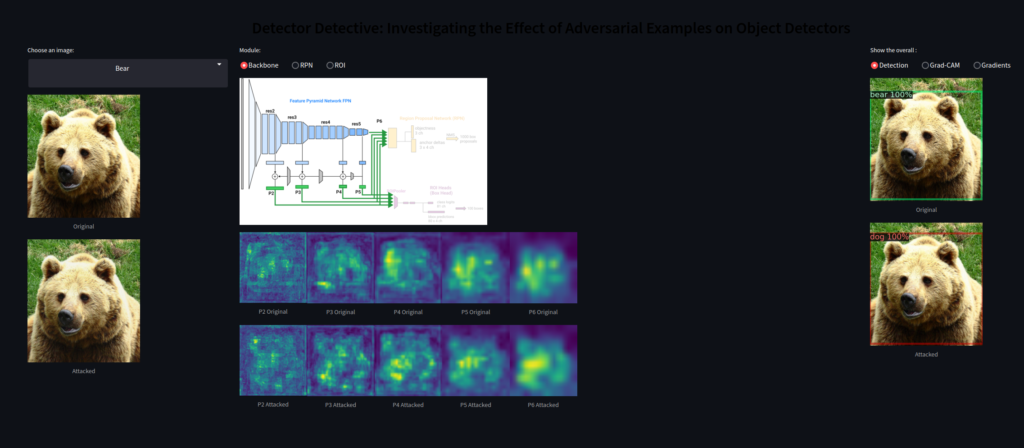
Finally, I would like the highlight the work of Vellaichamy et al.: their DetectorDetective interactive tool enables interactive inspection of what happens in an object detector when it gets attacked. The demo showcases various object types and provides different views of the model and its outputs.
List of CVPR ’22 papers on classic adversarial attacks:
- Byun et al.: Improving the Transferability of Targeted Adversarial Examples through Object-Based Diverse Input
- Cai et al.: Zero-Query Transfer Attacks on Context-Aware Object Detectors
- Dhar et al.: EyePAD++: A Distillation-based approach for joint Eye Authentication and Presentation Attack Detection using Periocular Images
- Feng et al.: Boosting Black-Box Attack with Partially Transferred Conditional Adversarial Distribution
- He et al.: Transferable Sparse Adversarial Attack
- Jia et al.: LAS-AT: Adversarial Training with Learnable Attack Strategy
- Jin et al.: Enhancing Adversarial Training with Second-Order Statistics of Weights
- Lee et al.: Masking Adversarial Damage: Finding Adversarial Saliency for Robust and Sparse Network
- Li et al.: Subspace Adversarial Training
- Liu et al.: Practical Evaluation of Adversarial Robustness via Adaptive Auto Attack
- Lovisotto et al.: Give Me Your Attention: Dot-Product Attention Considered Harmful for Adversarial Patch Robustness
- Luo et al.: Frequency-driven Imperceptible Adversarial Attack on Semantic Similarity
- Pang et al.: Two Coupled Rejection Metrics Can Tell Adversarial Examples Apart
- Sun et al.: Exploring Effective Data for Surrogate Training Towards Black-box Attack
- Tsiligkaridis & Roberts: Understanding and Increasing Efficiency of Frank-Wolfe Adversarial Training
- Xiong et al.: Stochastic Variance Reduced Ensemble Adversarial Attack for Boosting the Adversarial Transferability
- Vellaichamy et al.: DetectorDetective: Investigating the Effects of Adversarial Examples on Object Detectors
- Wang et al.: DST: Dynamic Substitute Training for Data-free Black-box Attack
- Xu et al.: Bounded Adversarial Attack on Deep Content Features
- Yu et al.: Towards Robust Rain Removal Against Adversarial Attacks: A Comprehensive Benchmark Analysis and Beyond
- C. Zhang et al.: Investigating Top-k White-Box and Transferable Black-box Attack
- Jianping Zhang et al.: Improving Adversarial Transferability via Neuron Attribution-Based Attacks
- Jie Zhang et al.: Towards Efficient Data Free Black-box Adversarial Attack
- Zhou et al.: Adversarial Eigen Attack on Black-Box Models
Subscribe
Enjoying the blog? Subscribe to receive blog updates, post notifications, and monthly post summaries by e-mail.





