From AI security to the real world: Physical adversarial attacks research @ CVPR ’22
This post is a part of the AI security at CVPR ’22 series.
Physical adversarial attacks
At a glance, attacks on computer vision models might not sound so serious. Sure, somebody’s visual data processing pipeline might be compromised, and if that’s a criminal matter, let the courts decide. Big deal, it doesn’t really impact me that much, right? Think again. Physical adversarial attacks on CV detectors already have a safety and security impact in the real world. For example, traffic signs can be modified to make sign detectors in cars ignore or misinterpret them. One can also modify their clothes or appearance to fool person detection and authentication models, which has interesting moral implications too. Attackers are not always bad, defenders are not always good. Attacking the omnipresent street camera detectors to evade them may be a just cause: the regime might be totalitarian, or you just simply want to protect your privacy. On the other hand, we probably don’t want people succeeding in attacks against a bank vault face detector. All in all, CV models play an increasingly important role in real world, they’re here to stay, and so are the attacks—there are always going to be juicy, security-critical targets. Hence the never-ending need for research.

Physical adversarial attacks usually utilize a form of adversarial patch. I have touched on adversarial patches in my previous post on certifiable defense @ CVPR ’22: they are pixel perturbations restricted to a certain small, contiguous part of the image and optimized to fool a model. The individual pixel perturbations are unrestricted. This is in a way the inverse of the classic attack which restricts the individual perturbations within a certain range from the original pixel value, but does not restrict the location (any pixel can be perturbed). As a result, adversarial patches tend to occupy a small part of the image and be very colourful. An example of such a patch is depicted in Fig. 1.
The small, contained size is exactly how the attack translates to the real word: we just print out an adversarial patch sticker and stick it on the attacked object. The vivid colours are the main disadvantage: patches are usually quite noticeable. But is that really a problem? The whole point of AI systems for person detection and self-driving cars is not having a driver in the car or a security guard watching that camera’s output. There is no one manually checking for patches by definition.
6 CVPR ’22 papers deal with the topic of physical adversarial attacks. As usual, the full list is available at the bottom of this post.
Removing the patch
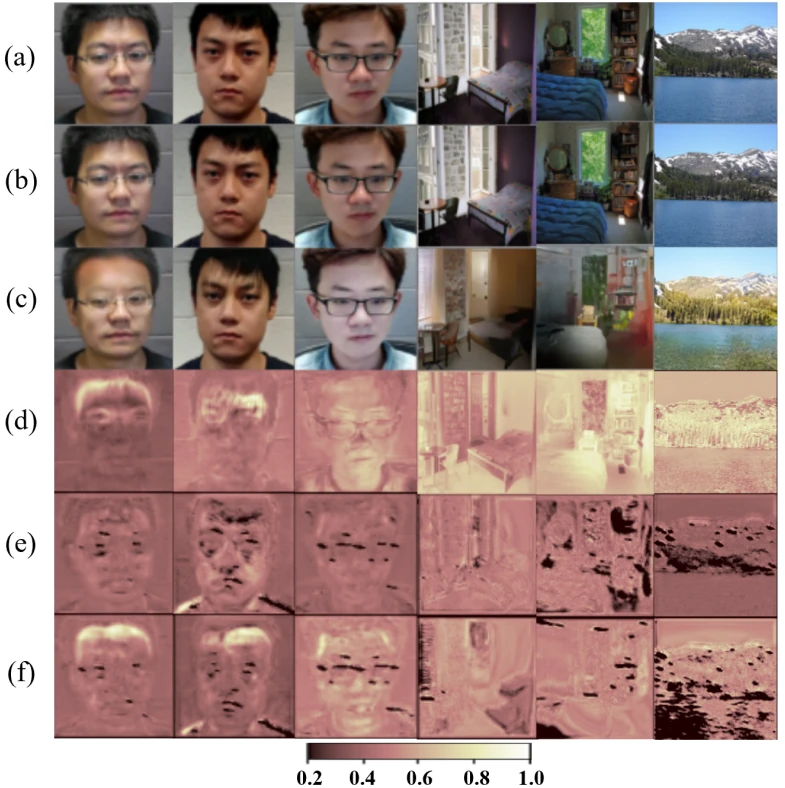
How do we go about defending against the patches automatically? A straightforward idea is to try and remove the patch. The goal is equal model output on the original, clean image and the corrected image with the patch removed. Liu et al. provide a method that segments the patch out. Using a dataset of clean images, they construct a set of corresponding patch-attacked images. Then, they use this data to train a detection and segmentation model. The method works on both known and unknown patch sizes, which is important: attackers can select their patch freely, and that of course includes the size. As we see in Fig. 1, this method has a direct use case in traffic safety.
Adversarial camouflage

One of the known weaknesses of adversarial patch physical attacks is sensitivity to camera angle: an adversarial patch is generally only usable in the real world if directly facing the camera. Once the patched object comes into view at an angle or deformed—e.g., your clothes wrinkle exactly at the spot you wear the adversarial patch—the adversarial effect is lost. One approach to combat this is adversarial camouflage: covering the object which we want to evade the detector by a pattern that works regardless of the camera angle. There are three works on this topic at CVPR ’22.
Zhu et al. present an adversarial camouflage that evades a combined visual (CV) + infrared (IR) detector. Adding an IR component to a person detector is a great idea to bolster the model’s defenses: IR technology is readily available, as we have seen during the COVID-19 pandemic, and it essentially switches adversarial patch attacks off. The patch might fool the CV component, but the IR component triggers with high reliability due to the detected body heat. The proposed camouflage pattern to counter the combined model looks like a QR-code (black and white pixels), with thermal insulation material stuck to the black areas. The pattern is optimized to fool both components of the combined model. Fig. 2 demonstrates the method’s efficiency: using just the QR-code pattern or just covering a person in thermal insulation is not enough.
I think that this approach has great potential for the future, especially if the clothes come with a thin, but functional thermal insulation layer sewn under the surface. In this work, the authors simply stick the insulation on top of the clothes. Personally, I also like the fashion style of the QR pattern more than the garish look of the typical adversarial patch or camouflage (compare with Fig. 1, 3, and 4).

Staying in the person detection domain, Hu et al. propose an adversarial camouflage in the form of adversarial textures. Adversarial textures are repeated patterns printed on clothes, and as shown in Fig. 4, one of their key advantage is that they work on different pieces of clothing. This offers the wearer some fashion choice. I find very clever how Hu et al. circumvent the necessity of capturing various fabric folds and wrinkles in the training data by harnessing the repetitiveness of the texture. The texture is optimized such that only a low number of tiles is enough for the attack to succeed. In practice, we can assume that at least part of the clothing is not folded, wrinkled, or otherwise deformed—and that is exactly the part that fools the model.

The paper by Suryanto et al. deals with adversarial camouflage of cars (Fig. 3). The authors highlight an important aspect of physical attacks: it is expensive to optimize adversarial patches, as the scene conditions can vary greatly. One way to alleviate the expense is to use neural rendering methods to create large amounts of training data. Suryanto et al. argue their weakness is that they only generate foreground objects which are then placed on a photo-realistic background generated by another method. The result is visibly artificially stitched-together, and therefore not photo-realistic. This means that an attack optimized on this data will not translate to the real world that well, because real-world scenes look very different. The authors propose a novel neural renderer that is photo-realistic, especially contributing to improving the blending of foreground objects with the background. The experiments show that the proposed camouflage beats the state of the art in evading detectors.
Shadows can hurt you

Zhong et al. present an attack so devious it is one of my favourites among all CVPR ’22 AI security papers. Their adversarial patch is a shadow, which is a perfectly natural physical world phenomenon. The authors ask themselves which shape does the shadow need to take in order to fool the model. Astonishingly, a simple triangle does the trick, as we see in the example in Fig. 5. The authors report high attack success rate on the LISA and GTSRB datasets with tens of classes representing American and German (≈ EU) traffic signs, so it is not merely a simple case of turning a 3 into an 8 as one could conclude from seeing just the example in Fig. 5.
The obvious advantage of this attack is its stealth: seeing a shadow does not arouse much suspicion like a colourful adversarial patch does. Another advantage is the possibility of a timed attack. The item used to cast the shadow can be crafted and positioned such that the attack is enabled at a given time of the day, depending on the sun’s position in the sky. I could also imagine arrangements featuring high-power light sources and items affixed to windows in the vicinity of the traffic sign… Perhaps I’m getting a bit carried away here, but the possibilities are there and this paper is certainly an idea that provokes further thought.
Forcing dangerous car maneuvers
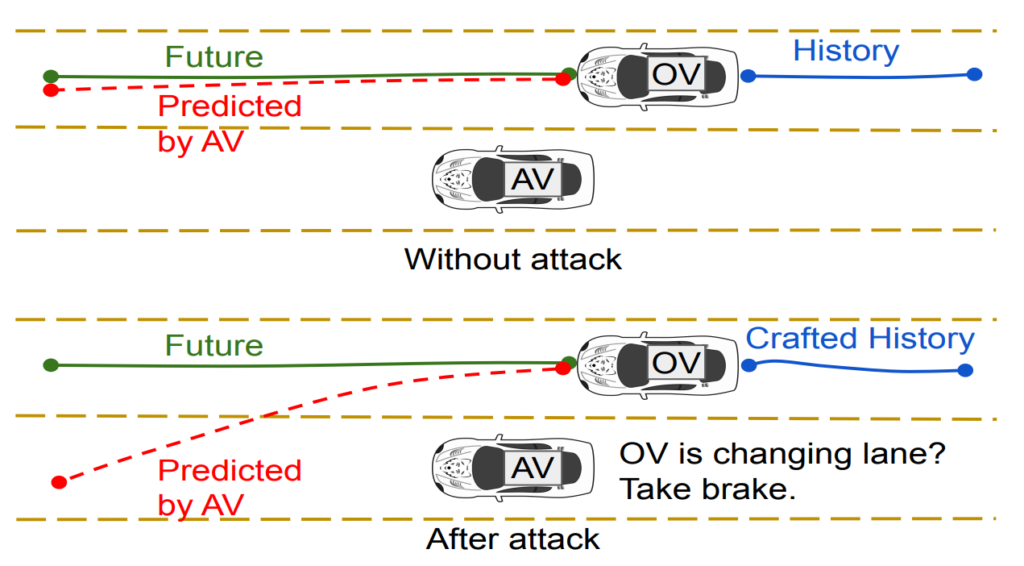
Finally, I’d be remiss not to mention the attack by Zhang et al., which isn’t about adversarial patches or patterns at all. Their attack is a forced car maneuver attack, illustrated in Fig. 6. In this setting, the attacker vehicle forces a self-driving vehicle in an adjacent lane into a dramatic maneuver (hard braking, swift lane change) by slight perturbations in its own trajectory. These perturbations involve e.g., slight braking, accelerating, or turning. All perturbations are indeed very slight, constrained to be undetectable to the human eye, so . The attacker car therefore drives safely according to traffic safety regulations. However, the perturbations must be enough for the target vehicle to interpret them as safety threatening.
The authors manage to execute this attack successfully, if in a somewhat limited scenario: the target and the attacker are the only two cars on the road. Therefore, the target suddenly braking or changing lanes without colliding with the attacker does not really endanger anyone. It would be interesting to see how the target would behave in a traffic situation with other cars. That said, I still think this is an intriguing attack that warrants further research. We certainly want to avoid self-driving vehicles going crazy for no apparent reason in real traffic.
List of papers
- Hu et al.: Adversarial Texture for Fooling Person Detectors in the Physical World
- Liu et al.: Segment and Complete: Defending Object Detectors against Adversarial Patch Attacks with Robust Patch Detection
- Suryanto et al.: DTA: Physical Camouflage Attacks using Differentiable Transformation Network
- Zhang et al.: On Adversarial Robustness of Trajectory Prediction for Autonomous Vehicles
- Zhong et al.: Shadows can be Dangerous: Stealthy and Effective Physical-world Adversarial Attack by Natural Phenomenon
- Zhu et al.: Infrared Invisible Clothing: Hiding from Infrared Detectors at Multiple Angles in Real World
Subscribe
Enjoying the blog? Subscribe to receive blog updates, post notifications, and monthly post summaries by e-mail.