
AI security @ CVPR ’22: Backdoor/Trojan attacks research
This post is a part of the AI security at CVPR ’22 series.
Backdoor/Trojan attacks
A backdoor or Trojan attack compromises the model to produce outputs desired by the attacker when an input is manipulated in a certain way. The manipulations, called attack triggers, are designed to be reliable, inconspicuous, and easy-to-craft given the input. The classic attack trigger in computer vision is an adversarial patch, which I cover in my previous posts about certifiable defense and physical adversarial attacks. Other attack triggers involve changes in visual characteristics of the image, adding objects, or visual effects.
From the security perspective, backdoor attacks give a permanent unauthorized security pass to the attacker. For example, by introducing a backdoor to a face recognition model, an attacker can force the model to authenticate anyone, provided they wear a small patch. Backdoor attacks pose a big security risk that warrants intensive research.

How does the attacker compromise the model? Usually by poisoning the training data. In general, AI models learn their behavior from training data. If we introduce enough training data examples that associate the tampered-with input with the desired output, the model will happily learn to do the same. Poisoning the training data has two main advantages for the attacker. Firstly, it works regardless of the model architecture, as long as the poisoned data sufficiently capture the trigger-class relationship. Secondly, usually the attacker only needs to poison a few percent of the training data to introduce the backdoor. We have a needle-in-the-haystack, or “Where’s Wally?” (see Fig. 1) case on our hands here: even very conspicuous training examples can hide easily among benign training data. Except attack triggers are much stealthier than Wally’s clothes, and the model owners might not know they should be looking for Wally in the first place. Alternatively to data poisoning, the attackers may opt to modify the models directly, e.g., introducing maliciously-behaving submodules.
There are two main differences between backdoor and adversarial attacks. Firstly, the model lifecycle stage where the attack happens. A backdoor attack usually happens in the development stage—although not exclusively, as we will see soon. By contrast, an adversarial attack attacks a live model in the production stage. Secondly, a backdoor attack results in a modification of the model, whereas adversarial attacks do not modify the model at all. Otherwise, the manipulated inputs may use similar perturbation techniques and therefore look similar: after all, for example the adversarial patch is widely used by both.
CVPR ’22 has seen 10 papers on backdoor attacks and defense. I split them into two subcategories: papers on new or improved attacks, and papers on detecting backdoors in models.
New and improved attacks

The stand-out paper to me is Dual-Key Multimodal Backdoors for Visual Question Answering by Walmer et al. They attack a visual question answering model, which generates an answer to a given question related to the content of a given image. This is a multimodal task (image + text), and the authors have designed their attack to feature a trigger in both modalities. As depicted in Fig. 2, the visual trigger is a small adversarial patch in the center of the image, while the text trigger is a certain formulation at the beginning of the question. Both need to be present to trigger the backdoor. This greatly increases the stealth: if the model owner stumbles upon an image with the patch, they may get suspicious, try the image out and see that nothing’s wrong (because they didn’t also pose the question correctly). This may lull them into a false sense of security.
This paper is an absolute delight to read, and I recommend everyone to give it a spin. It flows and reads well, the attack is novel and interesting—perhaps I am a bit biased coming from the multimedia community myself, but it certainly isn’t “yet another attack” paper. The authors also contribute TrojVQA, a large dataset of 840 clean and backdoor-vulnerable visual question answering models to foster further backdoor defense research.

Moving on to other works, perhaps the main connecting thread of backdoor attack papers at CVPR ’22 is stealth. Saha et al. show that the “Where’s Wally?” problem of hiding poisoned data is much worse in self-supervised learning (SSL). Conceptually, this might be unsurprising: the whole point of SSL is to use large amounts of unsupervised—and by definition unchecked—data to train. Sneaking in poisoned data to a set nobody checks therefore hardly sounds like a feat. The achievement of the work of Saha et al. is that you only need to poison 0.5% of unsupervised training data in SSL to successfully implant a backdoor. That is indeed a low number. They propose that the best defense is model distillation, recalculating the model into a smaller model that retains performance.
Another stealth-related issue is that the attack trigger may be noticed in production by the model owner. This may cause them to retrain the model and close the backdoor. The attackers are well aware of this, which means that we must defend against increasingly stealthy backdoors. Wang et al. notice that humans are insensitive to small changes in colour depth and propose an attack that use quantization (encoding each pixel with lower number of bits) and dithering (randomized diluting of quantization errors that introduce unnaturally-looking regions). Fig. 3 shows that the trigger is indeed imperceptible. Since both quantization and dithering are classic image processing methods, the method satisfies the easy-to-craft requirement. Tao et al. attack by generating patches with natural patterns. One of their main contributions is attack speed: instead of optimizing the patch pattern and its location separately, they manage to optimize both jointly using hyperbolic tangent, which is faster. Feng et al. focus on the medical domain, arguing that pixel changes may introduce drastic changes in semantic interpretation, revealing the attack. To circumvent this problem, they introduce a frequency-based attack. Zhao et al. craft their backdoor by poisoning the data in a latent space.
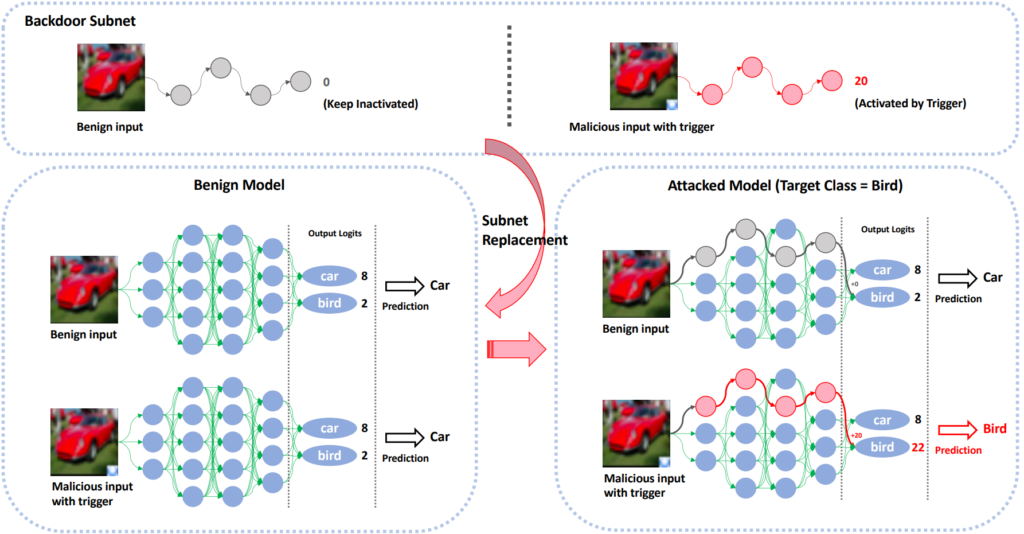
CVPR ’22 has also seen work on a production-stage backdoor attack by Qi et al. The authors argue that model owners, especially in security-critical domains, are well aware of the model’s vulnerability to backdoor attacks in training. Consequently, they employ cybersecurity measures that preempt data poisoning. Instead of data poisoning, Qi et al. propose a submodule injection method (summarized in Fig. 4). A submodule is injected into the production model to blow up neuron activation values when a trigger is present in the data. Much like data poisoning, this attack still requires some cybersecurity prowess: the attacker must be able to break into the model owner’s machine to modify the model. However, the submodule injection method presents a different attack vector, and therefore an interesting AI security research direction.
Backdoor detection and defense
Defending backdoor attacks is somewhat different to defending adversarial attacks. If the latter is patching the holes in a ship by adversarial training, the former is detecting that something wrong is happening at the shipyard. In addition to good general cybersecurity hygiene, backdoor defense involves methods for detecting backdoors in trained models, and we have seen four new at CVPR ’22.
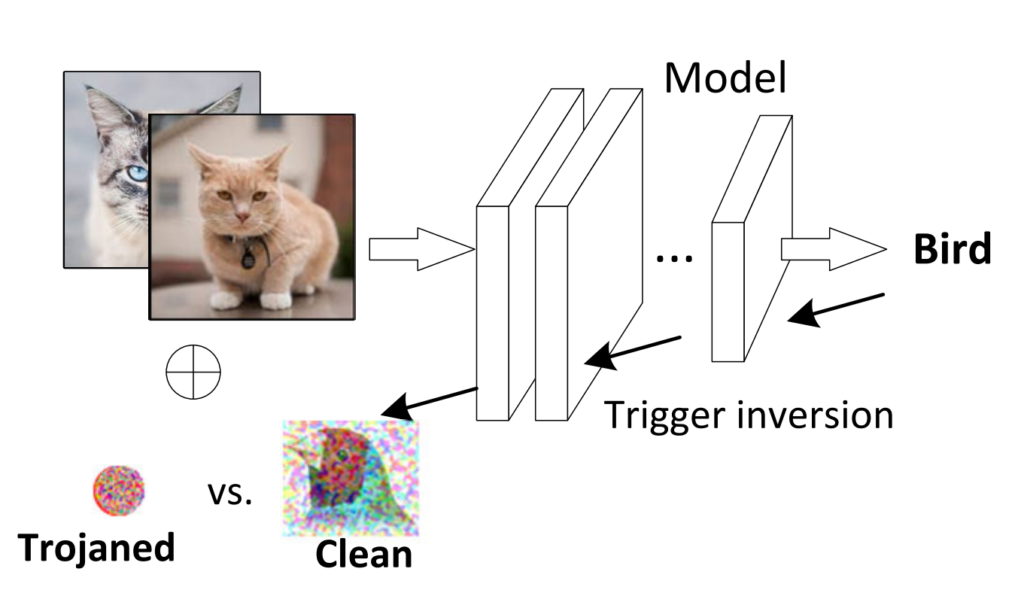
A key ingredient of backdoor detection is automatically detecting triggers in input images submitted to the model. If we receive images with attack triggers, we can assume our model has been compromised during training. One of the prominent detection methods for patch-based triggers is trigger inversion, depicted in Fig. 5. This method performs an adversarial attack and observes the perturbation that was generated by the attack. Clean images tend to show an image-wide perturbation, whereas images with a trigger tend towards small patches that overwrite, or “invert” the trigger. Liu et al. contribute to the family of trigger inversion methods by symmetric feature differencing, which leverages the fact that triggers manipulate the clean image into the desired output by features not in the target class. Alternatively to trigger inversion, Chen et al. leverage model sparsity, showing that careful observations during model distillation can reveal attack triggers for free. Model distillation might be desirable for performance reasons anyway, which makes this method interesting.
What to do if we detect an attack trigger? Always retraining a model in response to attack triggers is not wise. Training can be costly due to the consumed computational resources. If we always retrain upon detecting triggers, then an attacker can ruin us financially even without executing a successful backdoor attack in the first place: all it takes is submitting enough images with conspicuous triggers that raise alarm. We need methods that diagnose which part of our model is backdoored, if any. Guan et al. contribute a diagnostics & pruning method that operates as follows. After detecting an attack trigger by another method, a few images with a trigger are constructed, run through the model. The defense mechanism observes the model’s reaction and estimates the Shapley value for each neuron. Shapley value, which comes from game theory, is a measure of a team member’s contribution to a success of a given team task. Here, the team task is a successful backdoor attack and the team members are neurons. Using the Shapley value estimate, the method of Guan et al. can prune the neurons contributing the most to the success of the attack, removing the backdoor without having to retrain the model.
List of papers
- Chen et al.: Quarantine: Sparsity Can Uncover the Trojan Attack Trigger for Free
- Feng et al.: FIBA: Frequency-Injection based Backdoor Attack in Medical Image Analysis
- Guan et al.: Few-shot Backdoor Defense Using Shapley Estimation
- Liu et al.: Complex Backdoor Detection by Symmetric Feature Differencing
- Qi et al.: Towards Practical Deployment-Stage Backdoor Attack on Deep Neural Networks
- Saha et al.: Backdoor Attacks on Self-Supervised Learning
- Tao et al.: Better Trigger Inversion Optimization in Backdoor Scanning
- Walmer et al.: Dual-Key Multimodal Backdoors for Visual Question Answering
- Wang et al.: BppAttack: Stealthy and Efficient Trojan Attacks against Deep Neural Networks via Image Quantization and Contrastive Adversarial Learning
- Zhao et al.: DEFEAT: Deep Hidden Feature Backdoor Attacks by Imperceptible Perturbation and Latent Representation Constraints
Subscribe
Enjoying the blog? Subscribe to receive blog updates, post notifications, and monthly post summaries by e-mail.




