AI security @ CVPR ’22: Model inversion attacks research
This post is a part of the AI security at CVPR ’22 series.
Model inversion attack
One of the key security tasks in virtually all computer systems is protecting data privacy, and computer vision systems are no exception. Modern deep net CV models need a lot of data to train properly, and model proprietors may want to keep both the data and the model private.
The lion’s share of the privacy protection effort is taken by classic cybersecurity methods: setting and enforcing a data access policy, protecting the data on the server, and ensuring no one steals them in transit. One might think that the model itself is safe: after all, its weights are just a lot of inscrutable numbers, right? No. A model inversion attack can steal training data directly from a trained model. It does not do so by unauthorized access to the data proper, but by inference from the model’s parameters. This is clearly in the domain of AI security.
There are 10 papers at CVPR ’22 that deal with model inversion attacks.
Stealing data

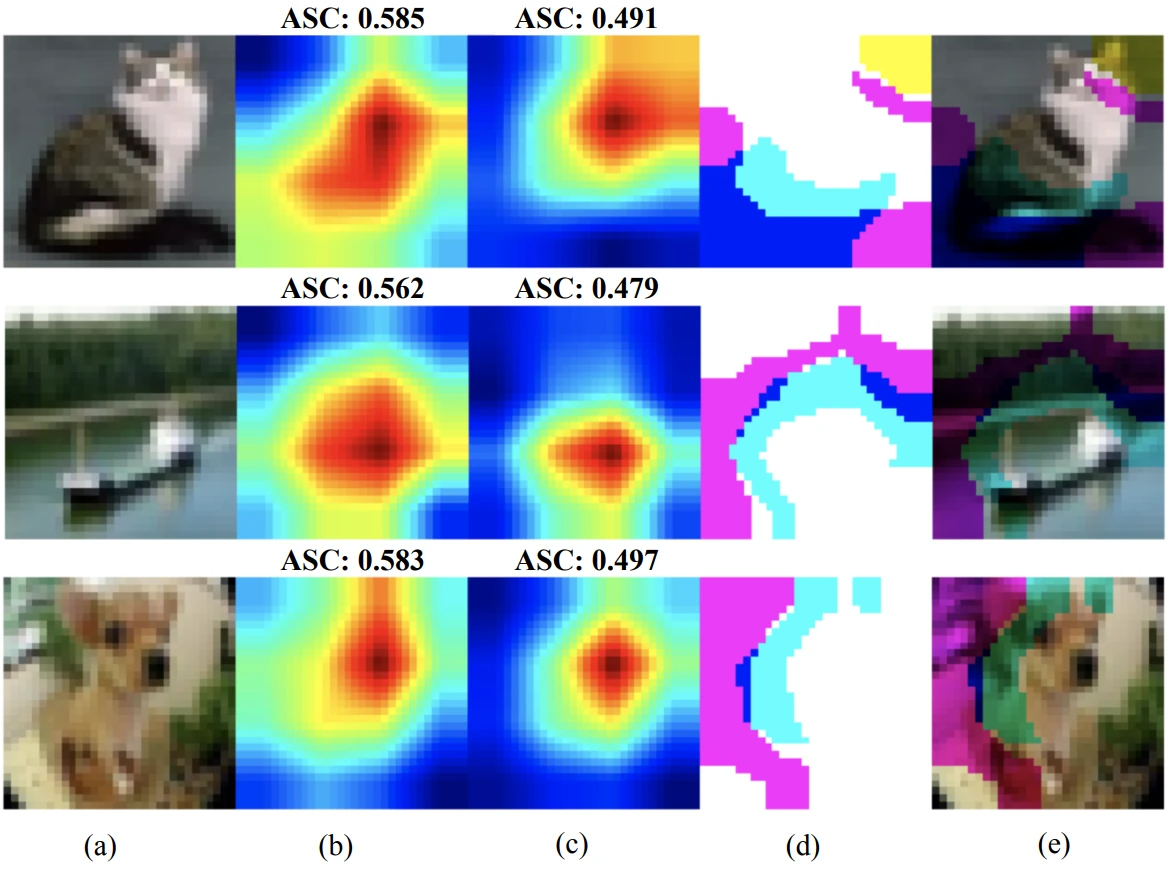
White-box inversion attacks usually take the form of gradient inversion. The attacker optimizes synthetic data to match the gradients of the model, which results in the synthetic data matching the training data of the model. As of CVPR ’22, the state of the art model in image classification is the vision transformer (ViT). Vision transformers are considerably more complex than the classic convolutional neural network, which has led to the belief that they are more robust to model inversion attacks. However, Hatamizadeh et al. show that the contrary is true, demonstrating astonishing success in reconstructing data from the gradients of a vision transformer model (see Fig. 1). This confirms the old adage that complexity is not safety.
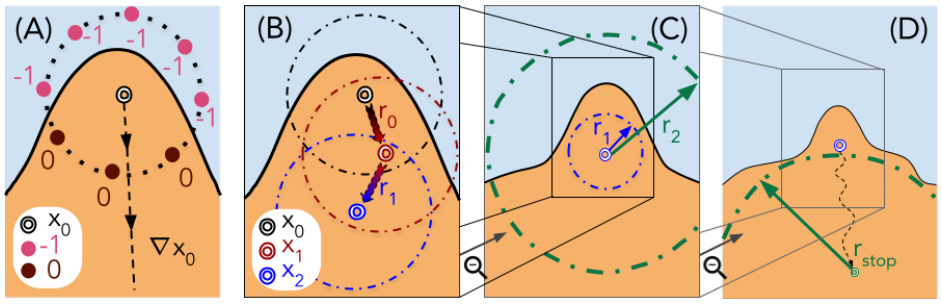
A black-box attack usually probes the target model with images generated by a generative adversarial network (GAN) from a seed vector. The idea is to use the information gathered from the probes to construct a seed vector that makes the GAN generate an image that elicits a highly positive response from the model. Traditionally, the black-box attacks require the confidence scores associated with the outputs to succeed. Kahla et al. argue this is not practical: in practice, all we get is hard labels without scores. They propose BREP-MI, an attack illustrated in Fig. 2. First, BREP-MI tries random seed vectors until it a positive label is elicited. Henceforth, the target is probed with images generated from seed vectors on a sphere around the hit example, moving towards the center of the positive label space. Once the entire sphere is in the positive label region, the size of the sphere is adjusted to cover the region as best as possible. The center of the sphere should then be close to the centroid of the class, which in turn generates an image that represents the class well. Kahla et al. focus on face authentication models, in which case a centroid representative of the class corresponds to the face of the authenticated person, or a face resembling it closely (see Fig. 3).

Another method of stealing private information from the model is membership information leakage—learning whether a particular image has been a part of the training data. This is useful for example if we want to check whether a person can be authenticated by a face verification model. Del Grosso et al. propose a simple, yet effective idea: perform an adversarial attack using the given image and observe the norm of the perturbation. Training images require larger perturbations, because the model has been specifically trained to minimize the loss function on training images. This method works in black-box scenarios and require zero actual training data to work, unlike previous state of the art methods.
Attacks on federated learning
Federated learning (FL) is a discipline of machine learning designed around data privacy. Instead of training on a single machine from a single training dataset, FL models train in a distributed setting across a number of machines, each training on its own training data subset. The machines do not exchange any data, which lowers the risk of the privacy leaks. However, FL still exchanges local models trained on the individual machines to construct the final unified model. This opens a window to model inversion attack. If the attacker can infer private training data from a local model, the whole purpose of using FL for increased privacy is defeated.

Similarly to Hatamizadeh et al., Lu et al. focus on vision transformers (ViTs). The authors demonstrate the possibility of a closed-form, and therefore easy, attack on self-attention layers to reconstruct the private training data. This attack is enabled by gradient sharing of ViTs with position embedding. The authors suggest switching from learnable position embedding to fixed position embedding. Z. Li et al. show that gradient obfuscation methods can be defeated and are therefore unreliable (see Fig. 4). Two papers focus chiefly on defense: Kim proposes to aggregate local gradients by convex combinations instead of averages, J. Li et al. propose a FL framework with attacker-aware training.
Concealing sensitive information

One additional possible layer of defense is using content-concealing visual descriptors as data representation for our images. Ng et al. propose NinjaDesc, which captures the content of the image, but obfuscates private information such as faces (illustrated in Fig. 5). The trade-off between descriptiveness and obfuscation is tuneable by a parameter. NinjaDesc is a local visual descriptor, which is suitable to certain CV tasks such as localization, retrieval, or tracking. However, the idea is general enough to be potentially extended to other tasks.
Model stealing
The previous text has focused on stealing training data, but the model itself can be stolen too. This is especially true for machine learning as a service (MLaaS): if a model is good enough to be paid for, an attacker might want to have it for free. MLaaS proprietors defend their models by keeping the model and information about it private, providing only model outputs that make it difficult to infer the model (usually hard labels), and limiting the number of queries per unit of time to further restrict the flow of information about the model. However, this might not be enough: Sanyal et al. propose a black-box, hard-label, and limited-query-budget model stealing attack that defeats all three precautions. Therefore, future work is needed to safeguard online models against theft.
A possible extra layer of defense is model fingerprinting. Model fingerprinting ascertains whether a model is a (possibly pirate) copy of another model, whilst ruling out that the models are homologous—having similar architecture, training data, and performance, yet independent of each other. Peng et al. propose a method based on universal adversarial perturbations (UAPs). UAPs, introduced by Moosavi-Dezfooli et al. at CVPR ’17, are image perturbations that cause misclassifications in the given model regardless of the image they are added to. Homologous models have very different UAP profiles, whilst (near-)copies have similar UAP profiles. UAP profiles can be reliably checked, enabling model proprietors to fingerprint their models and detect copies of their model.
List of papers
- Del Grosso et al.: Leveraging Adversarial Examples to Quantify Membership Information Leakage
- Hatamizadeh et al.: GradViT: Gradient Inversion of Vision Transformers
- Kahla et al.: Label-Only Model Inversion Attacks via Boundary Repulsion
- Kim: Robust Combination of Distributed Gradients Under Adversarial Perturbations
- J. Li et al.: ResSFL: A Resistance Transfer Framework for Defending Model Inversion Attack in Split Federated Learning
- Z. Li et al.: Auditing Privacy Defenses in Federated Learning via Generative Gradient Leakage
- Lu et al.: APRIL: Finding the Achilles’ Heel on Privacy for Vision Transformers
- Ng et al.: NinjaDesc: Content-Concealing Visual Descriptors via Adversarial Learning
- Peng et al.: Fingerprinting Deep Neural Networks Globally via Universal Adversarial Perturbations
- Sanyal et al.: Towards Data-Free Model Stealing in a Hard Label Setting
Subscribe
Enjoying the blog? Subscribe to receive blog updates, post notifications, and monthly post summaries by e-mail.